What is AI Evaluation (Evals)?
February 3, 2026
In AI engineering, evaluation (or "evals") is an indispensable part of the development cycle for nearly every product.
Traditional software code is deterministic. Engineers can look at the code and be certain what output a given input will produce. However, because AI models produce non-deterministic outputs, when we provide a specific input, we cannot simply read the code to know what output the AI will generate.
Given this reality, traditional software testing methods like unit tests, integration tests, and E2E tests cannot guarantee that the output will meet expectations.
Yet when AI is integrated into a software product, teams still need to determine whether new changes achieve the desired results. In this scenario, a different mechanism is needed to ensure that modifications related to AI actually improve the product.
In the industry, this process is called evals (short for "evaluations"). Evals is the standard term used, though teams often refer to it directly as "evals" rather than the full translation.
What Exactly Is Evaluation (Evals)?
So what is "evals" in concrete terms? If we had to describe it in one sentence, evals are like end-to-end testing for AI. They assess output quality against predefined standards.
When evaluating AI output, determining what is "correct" involves more complex factors than it does for traditional software. Beyond the most basic objective, measurable errors, evaluation must consider aspects like style and adherence to best practices.
Let's start with the most basic type: "objectively measurable errors." Before ChatGPT entered the reasoning model era, forums frequently showed examples of these kinds of errors. One case that sparked lots of discussion in the community involved large language models consistently claiming that the English word strawberry contains only 2 r's, no matter how they were asked.

Yet objectively, strawberry contains 3 r's. From an evaluation perspective, the AI fails this test.
Now consider tasks involving subjective judgment. Suppose an AI agent is asked to implement a utility function called getUniqueValues. Under system prompt A, the AI generates this version:
const getUniqueValues = (arr) => [...new Set(arr)];
After modifying the system prompt, the AI generates this version:
function getUniqueValues_v2(arr) {
const result = [];
for (let i = 0; i < arr.length; i++) {
if (result.indexOf(arr[i]) === -1) {
result.push(arr[i]);
}
}
return result;
}
Which version is better? There's no single correct answer. If you asked different engineers, you'd likely get different opinions. Some might say the first version is better because it's more concise and Set offers better performance. Others might argue the second version is easier to read and makes it simpler to insert a debugger for step-through debugging.
Which output is judged as better depends on the standards defined by the product team and engineering organization.
Returning to our definition of evals: you first establish these standards, then after any code changes, you feed different inputs through the system and check whether the outputs meet expectations.
As the screenshot below illustrates, product leaders at OpenAI and Anthropic have both mentioned in interviews that writing evaluation standards (writing evals) is almost the most critical core skill in developing AI products.

Using Evals to Make Data-Driven Decisions
Evals are crucial and considered a core skill by major AI companies because they're the primary mechanism for maintaining product quality.
For example, when a new model is released by an AI vendor, how do you decide whether to adopt it? Without evals, this question is nearly impossible to answer. Even if the new model scores well on benchmarks, integration into your product might actually produce worse results than the previous generation. (When GPT-5 was released, countless users asked on social media how to revert to GPT-4o, which shows that good benchmark scores don't guarantee everything. Different scenarios can yield different results.)
Similarly, suppose your team wants to optimize the overall process by using shorter prompts or a cheaper model to reduce costs, but you don't want quality to suffer. To confidently determine that quality won't be impacted, you need evals to help.
In other words, without evals, you have no way to know whether changes are actually better or whether you can improve further. Decisions become based on feelings or guesses, which is far from ideal for a product.
Evals and Traditional Testing: Similarities and Differences
Beyond helping drive decisions, evals serve another purpose: systematically maintaining product quality. With comprehensive evals in place, any changes can be evaluated before going live, ensuring the released version won't be worse than the previous one.
The diagram below shows the core workflow of evals. If you look closely, this process is very similar to test-driven development (TDD) from traditional development (readers unfamiliar with TDD can review the relevant article). This has led to the industry term "evals-driven development" or EDD.
Simply put, EDD means writing your evaluation metrics first, then adjusting the product (such as changing models, system prompts, or tool integrations). Then you run evals to ensure that the adjustments actually improve quality. If they don't, you continue iterating until you pass the evals.
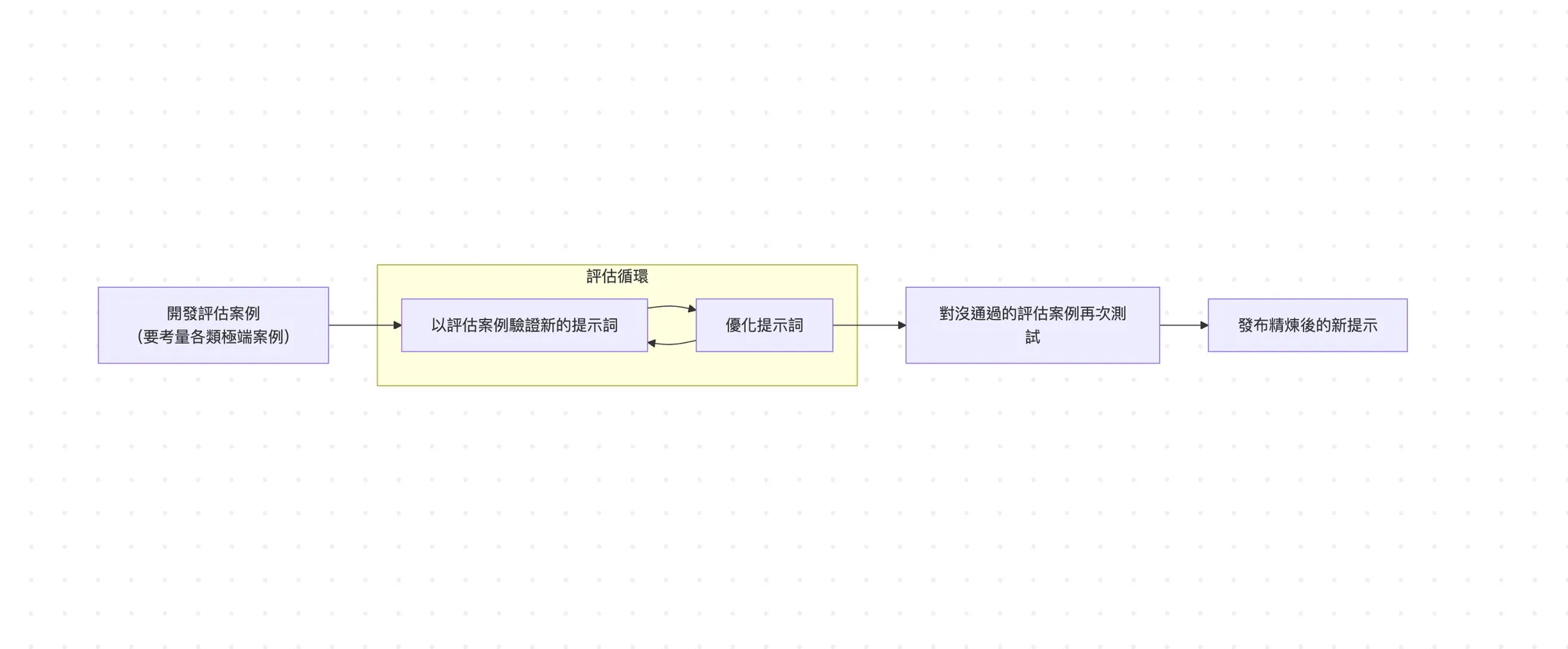
Amanda Askell from Anthropic once succinctly summarized it in a post: "The secret to a good system prompt is the boring but important method of test-driven development. Rather than writing your system prompt first and then testing whether it works well, write your test cases first, then find the system prompt that passes those tests."
