Database Sharding & Replication
February 14, 2023
In the load balancer section, we talked about how we can distribute requests to multiple servers when a website's traffic increases. However, if we have only one database and multiple servers, they will all operate on the database at the same time. Databases have their limitations, both in terms of hardware and the amount of data they can process simultaneously. Therefore, when the traffic grows, a single database may not be able to handle it. This is where we need to think about how to scale our database.
What Are the Methods for Scaling a Database?
We can try the following options to scale a database:
Vertical Scaling
This involves improving the hardware by upgrading to higher RAM or a larger storage space. This option may work for handling lower traffic. However, when dealing with large amounts of traffic, upgrading hardware has its limits.
Database Partitioning
This involves dividing a database into multiple smaller tables or instances, which can speed up data retrieval. With multiple instances, the database can handle a larger amount of data. Horizontal database partitioning, which involves splitting the database into multiple instances, is also known as database sharding and is the main topic of this article.
What is Database Sharding and Why Use It?
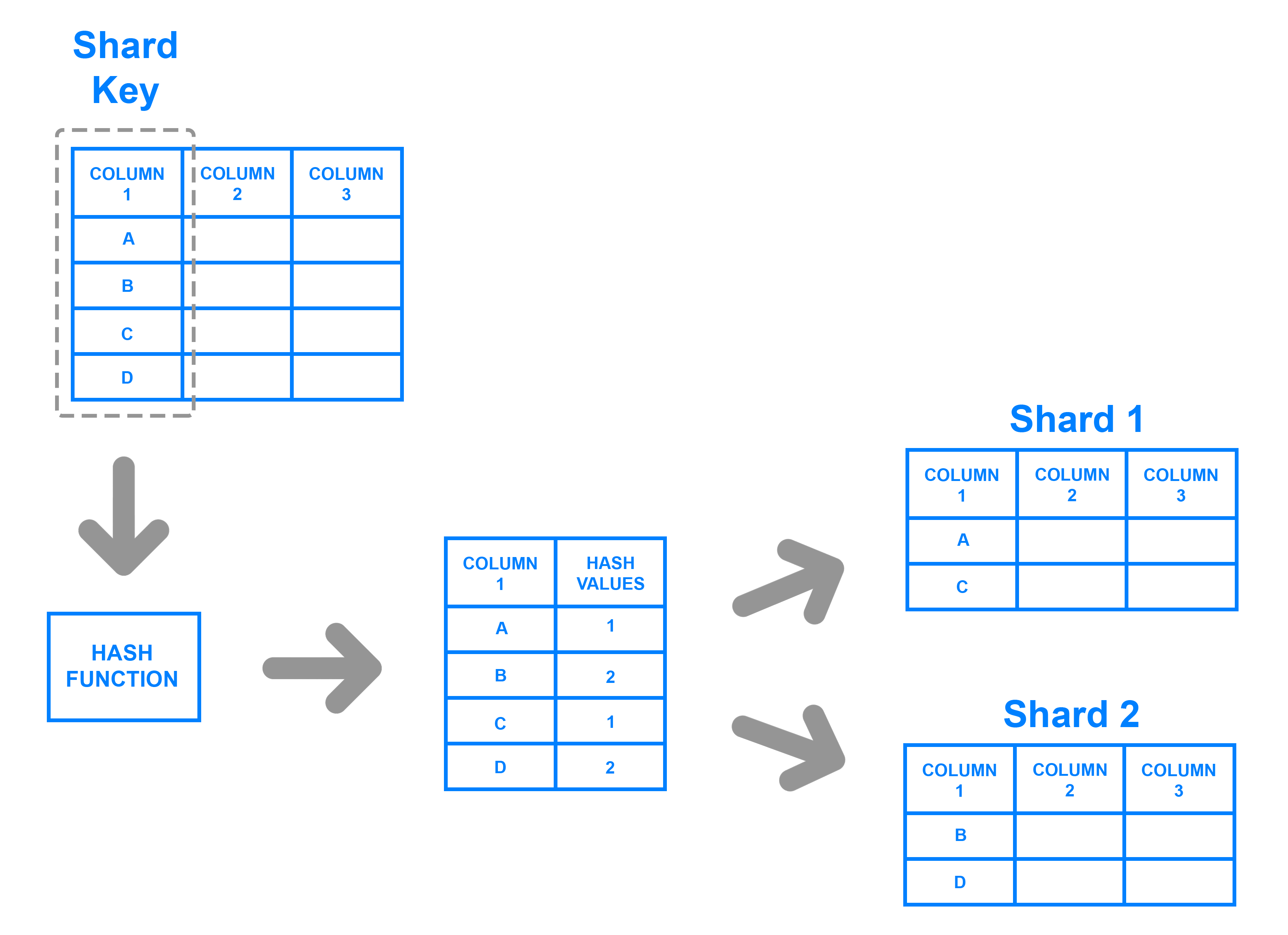
Database sharding is the process of dividing a database into smaller pieces, creating multiple database instances, and distributing the data among them. In the example provided by Digital Ocean, data A and B are placed in one shard, while data C and D are placed in another. Each shard is a separate database instance.
Sharding has several benefits:
- It can increase the number of operations a database can perform by allowing multiple database instances to work in parallel.
- It can improve performance if the shards are split effectively. For example, if international flights are placed in one shard and domestic flights in another, searching for international flights can be faster since the database is smaller.
- It can improve availability by avoiding the risk of having a single instance of a database. If one shard goes down, the other shards can continue to function.
Database Sharding Methods
Database sharding involves dividing a database into multiple smaller databases using a shard key. Common methods of shard key division include dividing data based on order, such as dividing age groups 0-10 in one shard and 11-20 in another, and business requirements such as dividing international flights into one shard and domestic flights into another. Hashing is also commonly used, with good hashing algorithms being able to distribute data evenly. Since hashing is an O(1) operation, finding the corresponding shard with a shard key is also fast.
Sharding Completed, But How to Address Single Point of Failure?
When a database is divided into multiple smaller databases through sharding, it still faces the problem of Single Point of Failure (SPoF). In other words, if a database goes down, such as the database that holds international flights, the data in that database cannot be requested from the server. To address this issue, we can replicate the database and place copies on multiple different machines.
Single-primary Replication
- One primary database can write data, while the other databases can only read. This method has an eventual consistency problem because database synchronization takes time. It is possible for a write request to have occurred but not yet been synced to the read databases, causing a read request to not receive the latest data. This is not an issue in some applications, such as seeing someone's Facebook comment a few seconds after they post it. However, it is not suitable for some applications that require high precision, such as in finance.
- Additionally, this method is only suitable for situations with a high volume of reads and low volume of writes, since reads can be distributed across multiple databases. However, if an application requires support for simultaneous writes, such as a chat room during the Super Bowl with thousands of people posting comments simultaneously, relying on one primary database for all writes is risky. If the primary database goes down, there will be no databases available for writing, since the other databases can only read. How can we address this situation?
Multi-primary Replication
- If only one primary database can write, there is still a risk of a single point of failure. Perhaps we can make multiple databases capable of writing, called multi-primary replication.
- However, this method presents the challenge of synchronizing databases with simultaneous writes. Additionally, how to handle race conditions across databases is also a problem to consider.