How Should Software Engineers Conduct Incident Reviews?
April 3, 2026
Previously, we covered How Should Software Engineers Do Monitoring? and How Should Software Engineers Handle On-Call?. This article continues that topic by focusing on what to do after an incident: the review.
In general, if an issue has little to no impact on end users, you may not need a formal incident review. But if the incident causes meaningful impact, a review becomes necessary. The goal is not to find someone to blame. The goal is to fully fix the problem and reduce the chance of similar incidents happening again.
In practice, incident reviews are called by different names: incident review, sev review ("sev" is the severity concept discussed in How Should Software Engineers Do Monitoring?), and postmortem.
The Core Nature of Incident Reviews
To do incident reviews well, you first need to understand what they are for. Incidents can hurt both individuals and teams. But nobody is perfect, and mistakes are unavoidable. Once an incident happens, the right focus is solving it and improving how the team works in the future.
Concretely, this means asking:
- How can we ensure this exact problem does not happen again?
- If complete prevention is unrealistic, how can we detect it earlier?
- Once detected, how can we resolve it faster next time?
Finding answers to these questions is what incident reviews should optimize for.
Everyone involved should come in with a "learn from mistakes" mindset. What the team learns should also be shared beyond the immediate group. That is why many mature organizations keep detailed review records, so other teams and departments can learn from the same incident.
Blameless Incident Reviews
When discussing incident reviews, one key concept is unavoidable: blameless reviews.
As mentioned earlier, the purpose of an incident review is to prevent repeat incidents. Based on that purpose, teams should avoid turning reviews into hunts for a culprit. There are no perfect people and no perfect processes. Mistakes happen. The team should focus less on who made a mistake, and more on how to prevent the same mistake from recurring.
After Meta's global-scale outage in 2021, Engineering VP Vijaye Rau shared thoughts on blameless SEV reviews (link). He noted that asking "who caused this incident" during the review does not help solve the problem, and can discourage teams from taking thoughtful innovation risks.
Taiwan's software history also has a well-known example: the Trend 594 incident. An engineer at Trend Micro released insufficiently tested code, which caused customer system failures and wiped out roughly NT$17 billion in market value. In an interview report (link), the CEO described why she deliberately avoided blame:
"I knew that if I asked, 'Who wrote this? Why was this released without adequate testing?'," "the company would be finished."
Even 8 years later, only a few executives knew who the engineer was.
That failure pushed the company to rethink architecture and eventually helped it lead the industry's cloud transition.
This is a strong example of what blameless review means in practice and why it matters. In blame-heavy cultures, people tend to hide problems to avoid punishment. That behavior makes incidents harder to resolve. Healthy engineering cultures do the opposite: no personal blame, strong focus on the problem itself.
In 2026, Claude Code, one of the most discussed AI agent tools, had a deployment mistake that exposed source maps and made previously closed-source code public. Many people in the community speculated whether the engineer behind the deployment would be fired.
Boris Cherny, creator and owner of Claude Code, responded publicly: mistakes are inevitable. As a team, the key is recognizing that root causes usually live in process, culture, or infrastructure, not in one person. In this case, a manual deployment step should have been better automated, and the team had already started making that improvement.
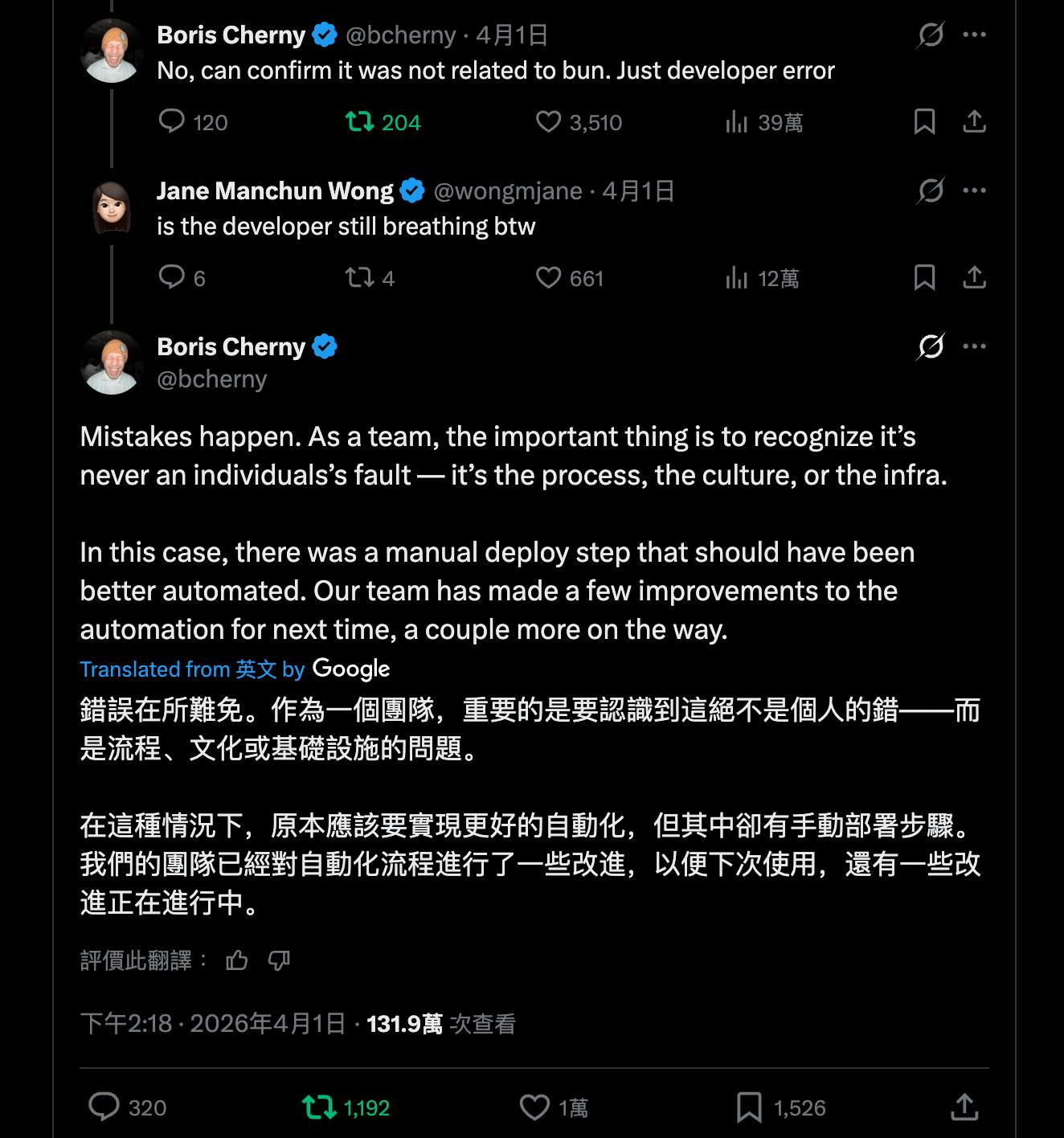
That response reflects a principle worth learning from: avoid blame, improve the system, and prevent repeat incidents.
Read More
If you want to go deeper, we have a more detailed E+ article that covers practical incident review meeting tactics, documentation practices, and recommended industry resources.
Support ExplainThis
If you found this content helpful, please consider supporting our work with a one-time donation of whatever amount feels right to you through this Buy Me a Coffee page.
Creating in-depth technical content takes significant time. Your support helps us continue producing high-quality educational content accessible to everyone.