What is the CAP Theorem?
February 23, 2026
What is the CAP Theorem?
The CAP theorem states that in a distributed system involving read and write operations, you can guarantee at most two of three properties: Consistency, Availability, and Partition Tolerance. The third must be sacrificed.
- Consistency: For a given client, read operations always return the result of the most recent write operation. Using a social media example, if you like a post and other users immediately see the updated count, the system maintains consistency. If other users don't see the update right away, consistency is broken.
- Availability: Non-failed nodes can respond to requests within reasonable time limits with valid (not error or timeout) responses, keeping the system operational. For a social media site, if you try to like a post but can't, the system lacks availability.
- Partition Tolerance: When network partitions occur (packet loss, disconnected links, congestion, etc.), the system continues to function and provide reasonable responses.
Consider a concrete example: designing an ATM system deployed globally. Each ATM is a node connected through a network that knows the current system state.
If the network connection fails, an ATM at location A cannot know the state of other ATMs. If user X withdraws money from ATM A, then walks to ATM B thinking they need more cash, and withdraws again, ATM B won't know to deduct the previous withdrawal from the balance. This creates a balance inconsistency.
This scenario sacrifices consistency to maintain availability. For an ATM system, this is unacceptable, so most ATM systems choose to maintain consistency instead.
However, maintaining consistency requires sacrificing availability. If a network partition occurs, the system must temporarily lock all ATMs to prevent withdrawals, ensuring balance consistency across all machines. But if users can't withdraw money, availability is compromised.
Applications of CAP
In distributed systems, you must choose to support P because networks cannot be 100% reliable. This means your system will be either AP or CP.
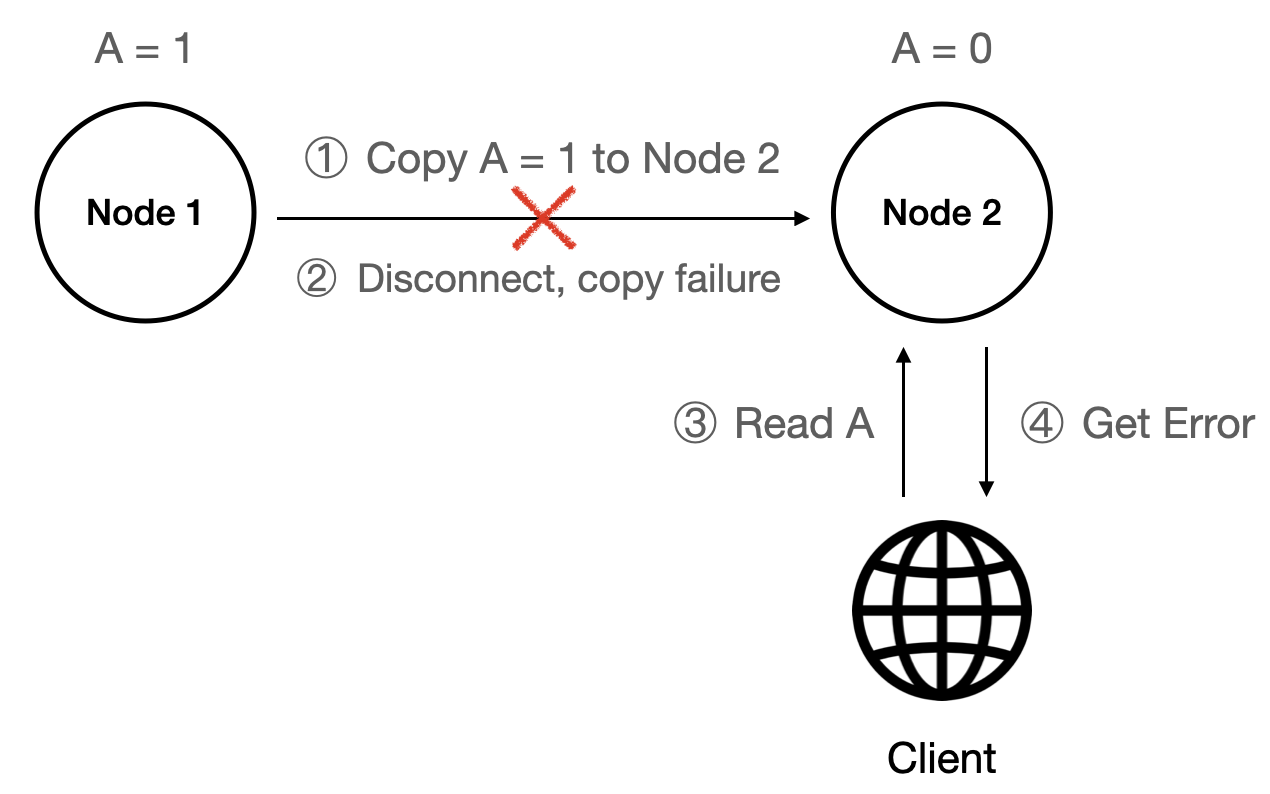
- CP: Node 1 updates
Ato1. When Node 1 tries to replicateAto Node 2 but fails, a client attempting to readAfrom Node 2 receives anErrorbecause the system prioritizes consistency.
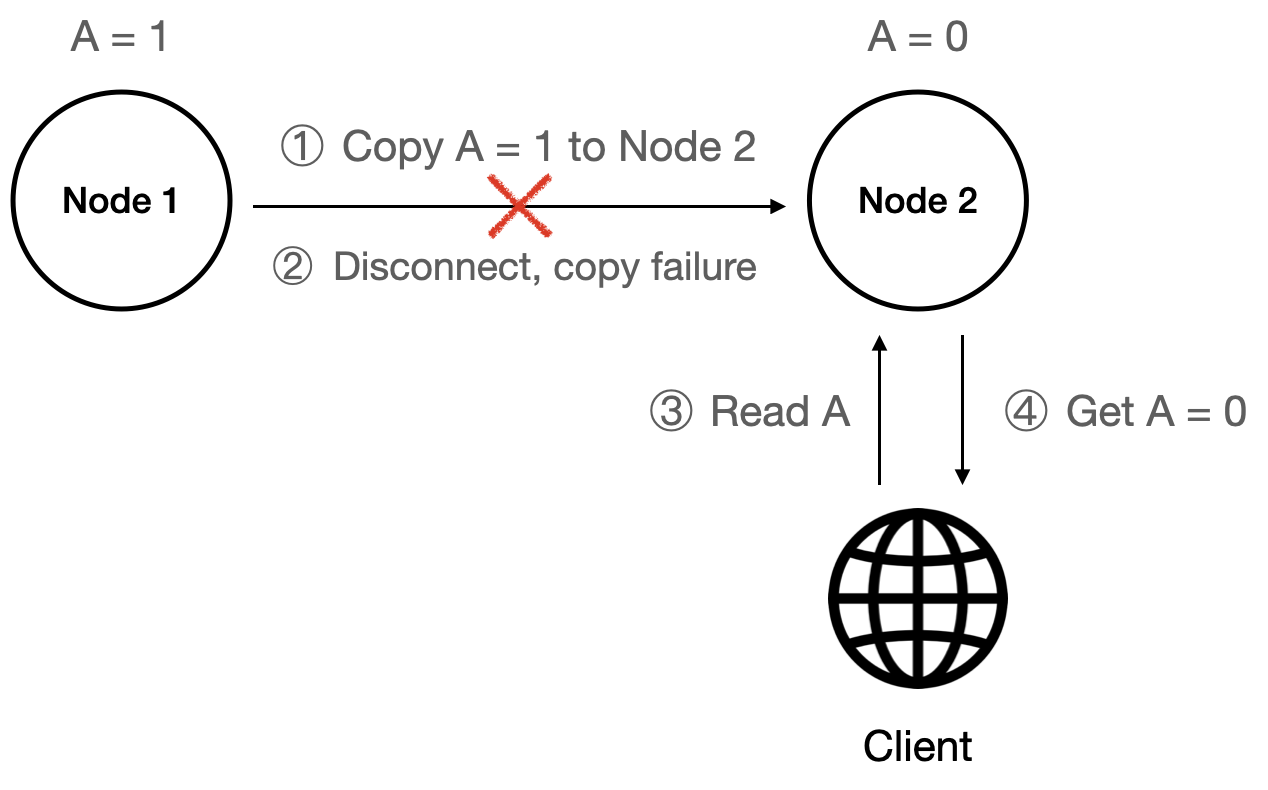
- AP: Node 1 updates
Ato1. When Node 1 tries to replicateAto Node 2 but fails, a client readingAfrom Node 2 receives the stale value0because the system prioritizes availability.
Using CAP to Guide System Design
Different Subsystems Have Different Strategies
When discussing CAP, people often frame it as a system-wide choice between availability and consistency. However, different subsystems can make different choices based on their requirements. Some parts may prioritize availability while others prioritize consistency.
Consider a ticket booking system. The core ticket-selling logic must prioritize consistency because inconsistency could lead to overselling. If two people simultaneously buy the last ticket, the system fails. However, the activity browsing page can prioritize availability. Some temporary inconsistency in listing the remaining tickets is acceptable, so this subsystem can be optimized for availability.
Even within a single system, different operations can follow different strategies. In the ATM example, during a network partition, withdrawals must maintain consistency to prevent overdrafts. But deposits could prioritize availability. An account balance inconsistency during deposit is less critical. After the network recovers, the system can synchronize the data. Deposits can therefore prioritize high availability.
Real Systems Are Never Perfect
When thinking about CAP, recognize that real systems are never perfect. Even without network failures, data replication always involves network latency, from milliseconds to tens of milliseconds. This creates brief inconsistency windows where perfect consistency is impossible. Yet systems still aim to be as consistent as reasonably possible. Assuming the ideal case where P doesn't occur, design the system to maximize CA guarantees.
Sacrifice Doesn't Mean Inaction
Systems don't remain in a failed state indefinitely. Failures happen and recovery must be planned. A user management system might start with CP. When a partition occurs, Node 1 can register new users but Node 2 cannot (A is sacrificed). When the partition heals, Node 1 has recorded all actions in a log. Once the partition recovers, the system syncs this data to Node 2. During the partition, Node 1 operates in CA mode.