What Is Blast Radius? How to Reduce It Strategically
May 9, 2026
As systems grow larger and dependencies become more complex, the term blast radius has become increasingly common in backend system design, DevOps, and SRE discussions.
Outside software engineering, blast radius usually brings to mind the physical range of a bomb explosion. But in software engineering, what does blast radius mean? Why does it matter to engineers? And what are common ways to reduce the impact of an incident? In this article, we'll start with a recent GitHub example and use it to unpack the concept.
What Is Blast Radius?
In software engineering, writing code is only one part of the work. To reliably deliver new functionality to users, teams need to care about more than implementation. Before an incident happens, testing and other practices can reduce the chance of failure. After an incident happens, rollback and recovery procedures can help the system return to a stable state more quickly.
But there is another important concern during the incident itself: limiting the scope of impact. That is what blast radius refers to in software engineering. It describes the area affected when an incident occurs.
For example, suppose a bug is discovered after a feature ships. If that bug only affects one page, the blast radius is relatively small. But some incidents affect more than a single page. They may span multiple pages in one product, or even spread across several products.
GitHub's recent incidents are a useful example. In late April 2026, GitHub experienced two incidents in close succession. One affected parts of the pull request and merge queue flow. Another involved an overloaded Elasticsearch subsystem, which caused several search-backed experiences across GitHub to fail, including parts of pull requests, issues, and projects. From a user's perspective, Git operations and APIs were still working, but because many UI experiences depended on search, the incident still caused significant disruption.
This is a classic example of an excessive blast radius. When a subsystem is not sufficiently isolated, a failure does not stay inside its own boundary. It spreads through hidden dependencies into other features. In "An update on GitHub availability", GitHub CTO Vlad Fedorov wrote that GitHub's priorities are availability first, capacity second, and new features third. He also emphasized reducing hidden coupling, limiting blast radius, and allowing the system to degrade gracefully when one subsystem is under pressure.
In recent years, several well-known incidents have shown blast radius at a global scale. In 2025, one especially memorable example was Cloudflare's global outage in November, which made more than half of the world's websites unavailable or unusable. Incidents with a worldwide blast radius are exactly what most software teams work hard to avoid.
Incidents are unavoidable. Even with strong testing, modern software systems depend on many external components. If a dependency fails, your own system can still be affected even if your team's code is working correctly. In 2024, Azure's West US region experienced a major data center power outage. Because Vercel's deployment platform partially depended on Azure services, Vercel was affected even though the failure was not on Vercel's side (link). In 2026, due to war, an AWS data center in the Middle East was affected and had to be shut down after a fire. These kinds of sudden events are difficult to predict.
Given all these unpredictable failures, software teams cannot stop at writing good tests. They also need to think about how to prevent incidents from spreading, and how to make sure users can continue using the product even when part of the technical system fails. In other words, effectively limiting blast radius is a challenge every software team has to face.
Concrete Ways to Reduce Blast Radius
Once we understand what blast radius is, the next question is obvious: how can teams reduce it? Put differently, when a failure or incident happens, how can we prevent its impact from expanding?
PlanetScale, a globally distributed database platform, discussed three principles in "The principles of extreme fault tolerance": isolation, redundancy, and static stability. Let's look at how these principles can be applied.
Isolation
When people talk about reducing blast radius, isolation is usually the first idea that comes to mind. The goal is to ensure that the impact of a failure stays within a specific area.
A common analogy in the software industry comes from shipbuilding. Modern ships use bulkheads to divide the hull into separate compartments. These compartments are isolated from one another. If a breach occurs, water only enters the damaged compartment instead of flooding the entire ship. At the same time, the remaining compartments help preserve the ship's stability, preventing one flooded compartment from sinking the whole vessel.
Applied to software engineering, this idea is often called the Bulkhead Pattern. For example, Microsoft Azure recommends that architects consider the bulkhead pattern when designing systems (link) so that failures can be localized.
Some people also describe this approach as Cell-based Architecture. The idea is to replicate the same system into multiple isolated, self-contained cells. Each cell can independently handle traffic and state. When one cell fails, the impact stays within that cell instead of taking down the entire system.
GitHub's current reliability work follows the same direction: isolate systems more thoroughly so that one slow or broken component does not drag down everything else. For example, GitHub has discussed moving webhooks to a separate backend, isolating critical services such as git and GitHub Actions from other workloads, reducing single points of failure, and accelerating the migration of performance- and scale-sensitive paths out of the Ruby monolith into Go services better suited for those workloads. At the core, these changes reduce coupling so that incidents are less likely to cascade across the platform.
The diagram below, from Azure's bulkhead pattern guidance, shows services A, B, and C split into three independent entities. If service A goes down, the blast radius is limited to A and does not affect services B or C.
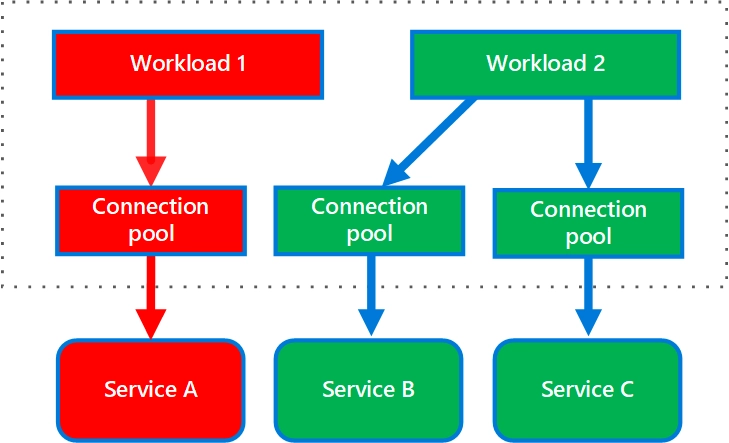
Earlier, we mentioned that Vercel had practiced failing over from Azure's West US region to the East US region. That kind of migration only works if a West US failure does not affect East US. In other words, it depends on isolation between the two regions.
This pattern is not unique to Azure. Major cloud providers generally use a shared-nothing architecture so that an incident in one region affects only that region. For example, AWS had an incident in the us-east-1 region in 2025. The impact was significant because many companies deploy resources there, but the incident stayed within that region and did not spread to other AWS regions. That containment was possible because compute and storage resources across AWS regions are designed to be independent.
Redundancy
Isolation often implies redundancy. Redundancy means the system keeps extra machines or components ready even when they are not actively serving traffic. When an incident happens, the system can quickly switch to standby capacity, preventing one failed machine or component from taking down the entire system.
Redundancy is usually paired with routing. When a primary dependency fails, routing can quickly shift traffic to a standby component. This is what people often mean by failover. In practice, many companies run regular failover drills to make sure the switch to redundant systems works when a real incident occurs.
Vercel wrote about this in "Preparing for the worst: Our core database failover test", which is worth reading. In that article, Vercel explained that the Azure West US incident mentioned earlier made the team realize the importance of drills. Although Vercel had redundancy available in East US, the team had not practiced the failover enough, so the actual switch was not smooth. That experience pushed them to rehearse regularly, so that when a real incident happens, the team is not scrambling.
Support ExplainThis
If you found this content valuable, please consider supporting our work with a one-time donation of whatever amount feels right to you through this Buy Me a Coffee page.
Creating in-depth technical content takes significant time. Your support helps us continue producing high-quality educational content accessible to everyone.