什麼是資料庫反正規化?優缺點是什麼?
2023年2月10日
💎 加入 E+ 會員方案 與超過千位工程師一同在社群成長,並獲得更多深度的軟體前後端學習資源
什麼是資料庫反正規化?
資料庫正規化是透過分表的的方式去做到降低資料的重複性、去除相依性等,但他的缺點顯而易見,表跟表之間的耦合性會很高、而且利用 JOIN 的方式查詢會導致速度變慢、拆成多張表的儲存成本也較高。
資料庫反正規化(Database Denormalization)是一種將資料庫中的資料再次加工,將資料從正規化狀態轉換為非正規化狀態的過程。而反正規化不等於非正規化(Unnormalized Form),反正規化是先遵守正規化的所有規則,再進行局部調整,故意打破一些正規化規則;而後者非正規化是全然不顧規則。
反正規化的邏輯在於:通過增加冗餘數據或對數據進行分組,犧牲一部分的寫入性能,換取更高的讀取性能。簡單來說,反正規化就是要把某些數據在不同地方多放幾份,加快數據檢索速度。
反正規化的優缺點
優點
- 查詢效能提升:通過將資訊放在一起,可能增加冗餘性。單因為
JOIN的數量減少,這會提高查詢效能。 - 方便管理:由於粒度高,正規化資料庫很難管理;相反的,反正規化可以提供易於使用的資料,而不是
JOIN完才能知道其資料的完整性。 - 提升報告化過程:分析資料需要迅速進行大量計算。反正規化資料庫生成報告是提供分析資訊的理想解決方案。
缺點
- 提升複雜性:在插入、更新資料時增加複雜性以及成本。
- 不一致性:因為數據難以更新,所以可能會有數據不一致的問題。
- 增加存儲負擔:由於增加了資料的冗余,因此需要更大的儲存空間。
反正規化的技術
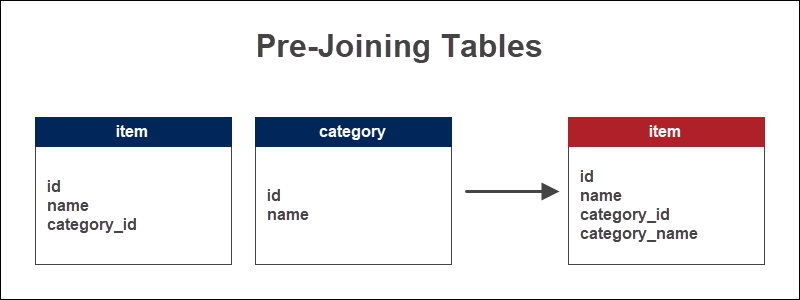
Pre-joining Tables
預先將兩張表或多張表 JOIN 起來,而會這樣做通常是因為:
- 在查找時,兩張表或多張表常常需要一起查找
JOIN時是需要耗費大量資源
如下圖所示,下圖將兩張表預先 JOIN ,這樣可以節省大量的時間和多次 JOIN 帶來的資料庫負擔。
Mirror Tables
Mirror Table 分成「部分複製」以及「全部複製」,常常是用來做備份。另外,有時會需要將數據做別的分析或者建模,因為需要將大量的資料做聚集,而這個步驟可能會導致系統效能降低,因此複製出來另外去處理,會使得原本的服務不會因為大量的計算而被中斷或者降低效能。
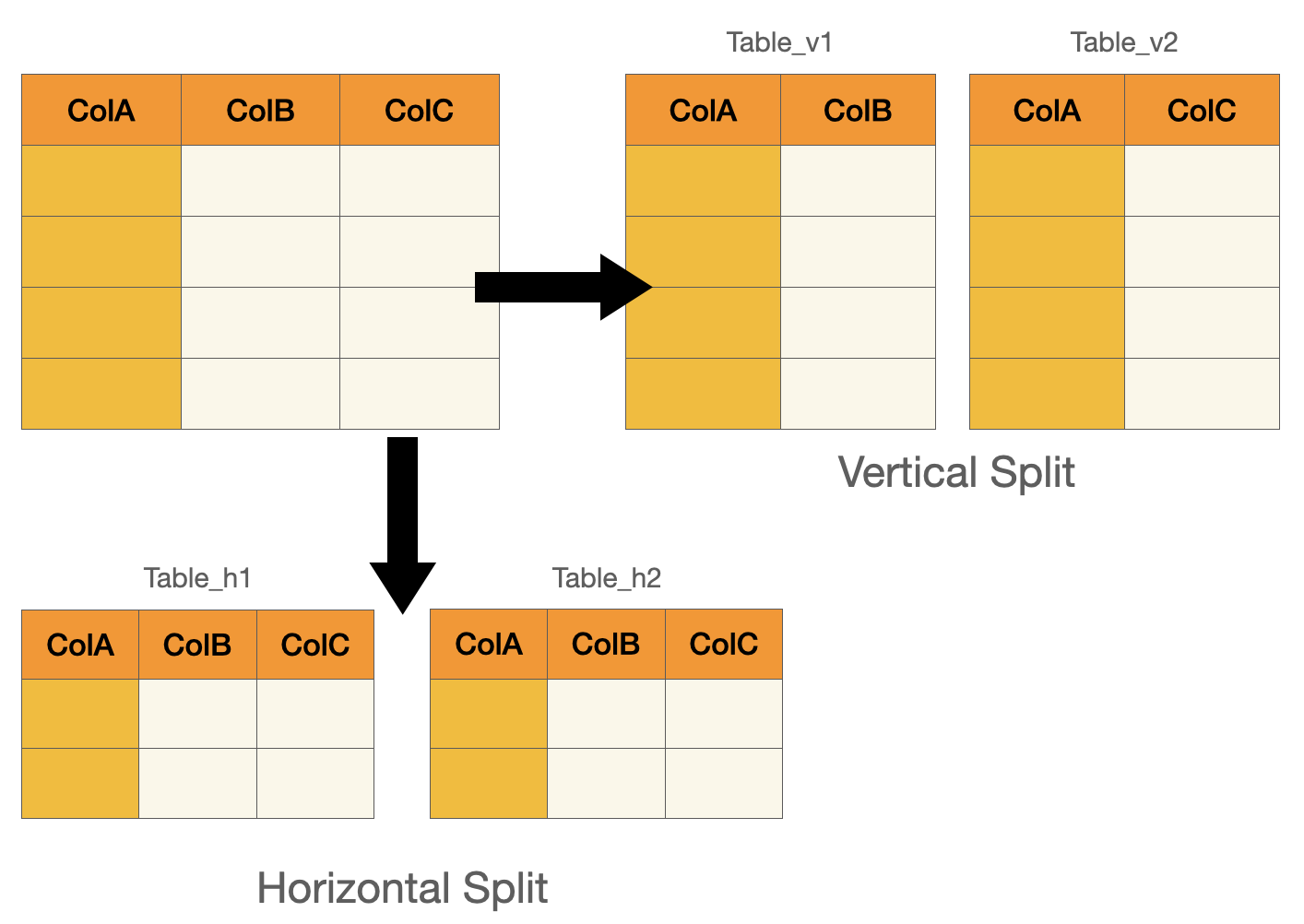
Table Splitting
常見的拆分方法有兩種:
水平切分:刻意將不同的 Row 拆分成不同的表,可以利用
ID的範圍或透過某些條件來拆分。垂直切分:將不同的 Columne 拆分成不同的表,Primary Key 也會重複出現在不同的表中。
Storing Derivable Values
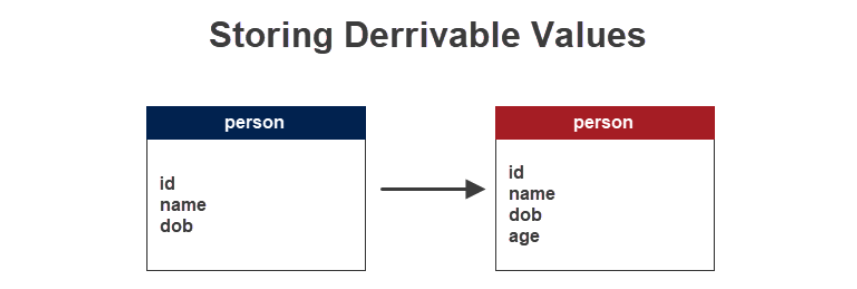
有些數值如果常常用到,就可以先計算好,例如:透過生日要算年齡,就可以新增一個欄位去存放年齡,而不用每次都重新算,如下圖所示: