什麼是爆炸半徑 (blast radius)? 如何有策略地縮減?
2026年5月9日
近幾年隨著系統規模越來越大、依賴關係越來越複雜,在後端系統設計,或者是 DevOps 與 SRE 相關領域的討論中,爆炸半徑 (blast radius) 變成經常被提到的詞。
假如是在非軟體工程領域的人,聽到爆炸半徑這個詞的時候,直觀會想到的炸彈爆炸時的範圍,但是在軟體工程的領域,爆炸半徑是在指什麼? 為什麼對工程師來說這個議題重要? 有哪些常見方法可以降低出事故的爆炸影響範圍? 這篇主題文中,我們將會從 GitHub 的近期案例談起,說明這個常聽見的詞與背後相關的議題。
什麼是爆炸半徑 (blast radius)?
在軟體工程中,寫程式只是其中一個環節,要確保軟體在新增功能後,能穩定可靠地交付給使用者,過程中有其他需要顧及好的面向。如果以階段的角度來拆分,在前期可以透過測試等手段,來降低事故發生的可能性;在後期則可以透過回滾 (rollback) 等方式,加速系統回歸穩定狀態。
除了事故前與後之外,在事故發生時,降低影響範圍也是軟體團隊應該關注的面向。在軟體工程中,爆炸半徑 (blast radius) 這個詞,就是在談論這個階段。爆炸半徑是指某一個事故發生時,被事故波及到的範圍。
舉例來說,假如今天某一個功能上線後才發現有 bug,如果這個 bug 只有影響所在的頁面,那麼爆炸半徑就不算太大;不過有些事故的影響可能不只是單一頁面,可能是橫跨某個產品的多頁面,也可能是橫跨多個產品。
以 GitHub 近期的事故為例,在 2026 年 4 月底 GitHub 接連發生兩起事故。其中一起讓部分 pull request 與 merge queue 的流程受到影響;另一起則是 Elasticsearch 子系統過載,導致 GitHub 上多個仰賴搜尋的體驗出現問題,包含 pull requests、issues、projects 等頁面的一部分搜尋結果無法正常顯示。從使用者角度看,明明 Git 操作與 API 沒有壞,但因為 UI 中有不少功能依賴搜尋,最後仍造成顯著干擾。
這正是爆炸半徑過大的典型問題。當一個子系統沒有被充分隔離時,它出問題後不會只停留在自己的邊界內,而是透過隱性的依賴關係擴散到其他功能。GitHub 技術長 Vlad Fedorov 在《An update on GitHub availability》中也提到,GitHub 接下來的優先順序會是可用性第一、容量第二、新功能第三,並且會透過降低隱性耦合、限縮爆炸半徑,以及讓系統在部分子系統承壓時能優雅降級,來改善可靠性。
在近幾年,有許多著名的事故,爆炸半徑更是擴及到全世界。以 2025 年來說,讓多數人印象最深刻的莫過於 Cloudflare 在 11 月的全球事故,該事故導致全世界一半以上的網站無法被瀏覽與使用,這種爆炸半徑大到全世界的事故,是多數軟體團隊會竭盡所能避免的。
由於事故是無法避免的,即使有再完善的測試,現代軟體系統往往有許多依賴,如果所依賴的元件出問題,即使自己團隊的部分做得好,也難以避免事故。在 2024 年時,Azure 的 West US 區域的資料中心遇到重大停電問題,當時由於部署平台 Vercel 部分依賴 Azure 的服務,所以當 Azure 資料中心出事,即使 Vercel 這一端沒有出任何錯,也導致 Vercel 無法被如預期使用 (連結)。甚至在 2026 年,因為戰爭的關係,AWS 在中東地區的資料中心被波及到,導致資料中心整個失火必須關閉。這種突如而來的意外是難以預期的。
在各種不可預期的事故下,軟體團隊不能只是把測試做好,而是要去思考問題發生時,可以如何避免事故的擴及,以及思考如何確保使用軟體產品的使用者,不會因為技術端的事故而無法繼續使用。換句話說,有效限縮爆炸半徑是每個軟體團隊必須面對的挑戰。
縮減爆炸半徑的具體方法
在了解什麼是爆炸半徑後,相信多數讀者會問「有哪些方法可以有效縮減爆炸半徑?」,換句話說如果出現故障或事故,可以如何有效避免影響範圍擴大?
全球規模的資料庫平台 PlanetScale 在《The principles of extreme fault tolerance》一文中談到他們使用的三大原則,分別是獨立 (isolation)、冗餘 (redundancy),以及靜態穩定 (static stability)。以下讓我們分別來看可以如何實踐這三個原則。
獨立隔離 (isolation)
當提到限縮爆炸半徑,相信多數人第一時間會想到的是透過獨立隔離的方式,讓影響範圍只會發生在特定的區域。
在軟體業界,有許多公司的做法會是參考造船的過程。現代船隻的設計,會為船設計艙壁 (bulkhead),把船體區分成多個船艙,使各個艙室彼此不會互通。在這種設計下,如果破洞發生時,水只會進到破損的那個艙室,不會影響到其他艙室;與此同時,當單一艙室進水時,其他艙室的結構能確保船體穩定,避免因為單一艙室進水而沈船。
把這個概念借用到軟體工程,就是很常會聽到的艙壁模式 (Bulkhead Pattern)。舉例來說,微軟的 Azure 就推薦架構師在設計架構時可以考慮艙壁模式 (連結),藉此來把事故局部化。
有些派別會把艙壁模式稱為細胞式架構 (Cell-based Architecture),之所以會這樣命名,是將同一套系統複製成多個彼此隔離、各自完整的細胞單元,每個單元都能獨立承載流量與狀態;當某個單元失效時,影響只會侷限在該單元,而不會拖垮整個系統。
回到 GitHub 的例子,GitHub 目前提到的改善方向也是把系統隔離做得更徹底,避免某個部分變慢或壞掉時拖垮其他部分。例如把 webhooks 遷移到獨立的後端、把 git 與 GitHub Actions 這類關鍵服務從其他工作負載中隔離出來、降低單點故障,並把對效能與擴展需求較高的路徑,從原本的 Ruby 單體加速拆到更適合這類工作負載的 Go 服務。這些做法本質上都是在降低耦合,讓事故即使發生,也比較不會牽一髮動全身。
下圖是來自 Azure 推薦的艙壁模式設計,透過把服務 A、B、C 分成三個互相獨立的實體,假如今天服務 A 掛掉,爆炸半徑就會被限縮在 A,不會影響到服務 B 與 C。
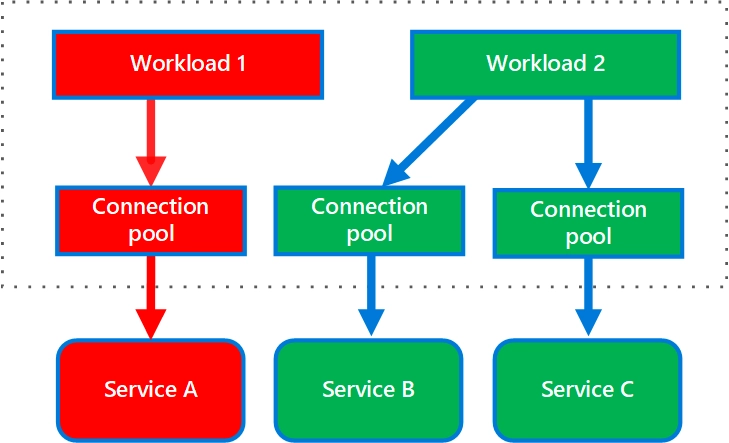
還記得上面有談到,先前 Vercel 有演練當 Azure 的 West US 區域掛掉,要無縫遷移到 East US 區域,這邊有的前提是 West US 區域掛掉不會影響到 East US 區域,這就透過兩者隔離才能做到。
事實上,不僅 Azure,各家雲端在架構上基本都是採取這種不共享 (shared nothing) 的架構,讓單一地區的事故,僅會影響該地區。例如 AWS 在 2025 年有個 us-east-1 區域的事故,雖然該事故的影響範圍不小 (因為很多公司把資源部署在該地區),但是當事故發生時,只有發生在該區域,沒有擴及到 AWS 的其他區域。之所以能不擴及,正是因為先前 AWS 各區域的運算與存儲都是獨立的。
冗餘 (redundancy)
前一段談到的獨立,背後意味著有冗餘。所謂的冗餘是指即使某些機器沒有被使用,但從系統的角度會先把這些機器預備著,當出事故時可以立即切換到正在待命的機器,避免因為一個機器無法響應,就讓整個系統無法運作。
冗餘一般會搭配路由 (routing) 來使用,當今天主要依賴的元件出問題,可以透過路由迅速切換到在一旁待命的元件,在英文很常聽到 failover 這個詞就是在講這件事。在業界,不少公司會透過定期的演練,來確保如果某個主要的依賴出事故,切換到冗餘的過程不會出問題。
Vercel 先前寫過《Preparing for the worst: Our core database failover test》一文,談他們如何具體做這件事,非常推薦一讀。在文中有談到,Vercel 之所以會開始做演練,正是前面談到的 Azure West US 區域出事故時,即使當時 Vercel 有 East US 區域的冗餘可用,但因為過往疏於演練,所以實際遇到故障時,沒有很順暢的切到 East US 區域的機器,該經驗讓 Vercel 的團隊意識到平常演練的重要性,這樣才能確保真的出事故時,不會手忙腳亂。
閱讀更多
如果對限縮爆炸半徑 (blast radius) 這個主題感興趣,我們在 E+ 會員方案中的主題文有談到更多具體實務的方法。對更深入了解這個主題,以及其他前後端開發、軟體工程、AI 工程主題感興趣的讀者,歡迎加入 E+ 一起成長 (連結)。