DDIA Ch3 Reading Guide — Data Models and Query Languages
April 14, 2026
In this chapter, the author focuses on data models and the query languages behind them. Like any other software system, data-intensive applications are built from layers of abstraction, and each layer needs its own model for representing data.
For example, application developers map real-world entities such as organizations, products, and money into program-level data structures. Once you make those decisions, you immediately hit the next layer: how should those structures be stored, such as JSON or XML? Go one layer deeper, and you need to decide how that data is represented in memory or on disk.
The industry has proposed many different data models over the years. Understanding how they differ, and what each one does well or poorly, leads to better technical decisions. Among all options, this chapter mainly covers three: relational, document, and graph models.
While reading this chapter, we were reminded of a common interview question: “What are the differences between SQL and NoSQL, and how do you reason about the tradeoffs?” You can think of this chapter as a deep answer to that question. (Note: NoSQL is a broad category. This chapter focuses on the most widely used document and graph NoSQL models, not every NoSQL type.)
Relational vs. Document
In relational modeling, SQL is still the dominant player. It has been widely used since the 1980s across all kinds of applications. We did see object databases in the 1990s and XML databases in the early 2000s, but neither displaced SQL in the long run.
By 2010, the term NoSQL (short for Not Only SQL) became a major topic in the community and kicked off a new wave of databases trying to challenge SQL’s dominance. Among many NoSQL systems, document models have remained especially influential, with MongoDB and Couchbase as common examples.
Where the Relational Model Feels Painful
To understand why document models gained momentum, it helps to start with the pain points of SQL systems. The community explored alternatives because relational systems can introduce friction in certain developer workflows.
One common criticism is mismatch: data is stored in relational tables, but application code needs a different shape, so engineers write extra transformation logic. The book uses Barack Obama’s LinkedIn profile as an example of this mismatch.
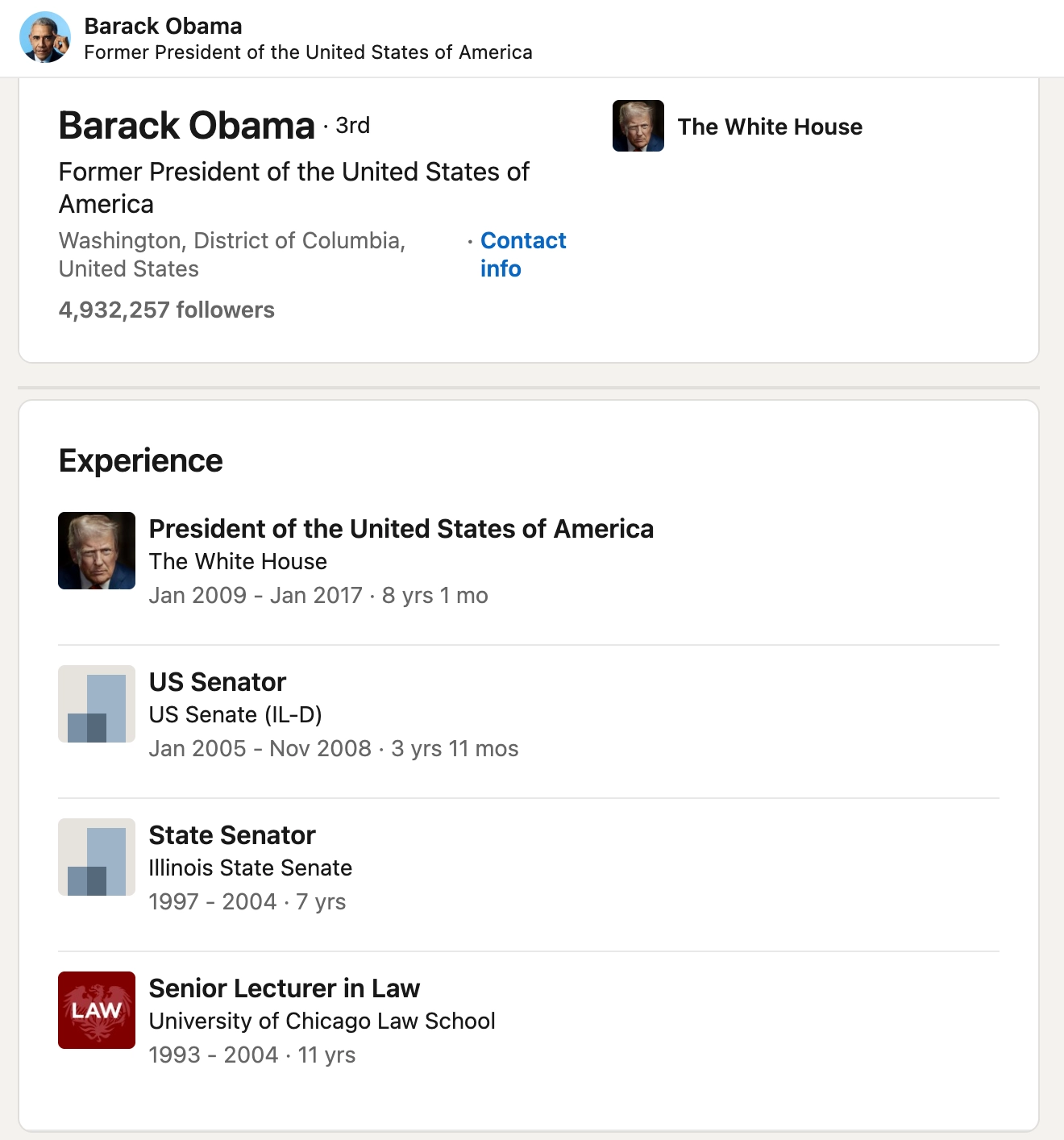
In a SQL schema, that profile is usually split across tables like users, regions, positions, education, and contact_info, then connected with foreign keys.
For instance, a user row often stores only a region_id, not the full region details. The application must then join against regions to fetch the human-readable region name. This is great for decoupling, but it means developers need additional code and queries to reconstruct data into application-friendly form.
SELECT users.*, regions.region_name
FROM users
JOIN regions ON users.region_id = regions.id
WHERE users.id = 251;
In a document database, the same profile can be stored directly as a JSON-like structure. That structure can often be consumed by the application as-is. In practical backend work, this can make API development simpler because the response shape is already close to what the frontend needs.
{
"user_id": 251,
"first_name": "Barack",
"last_name": "Obama",
"headline": "Former President of the United States of America",
"region_id": "us:91",
"photo_url": "/p/7/000/253/05b/308dd6e.jpg",
"positions": [
{"job_title": "President", "organization": "United States of America"},
{"job_title": "US Senator (D-IL)", "organization": "United States Senate"}
],
"education": [
{"school_name": "Harvard University", "start": 1988, "end": 1991},
{"school_name": "Columbia University", "start": 1981, "end": 1983}
],
"contact_info": {
"website": "<https://barackobama.com>",
"twitter": "<https://twitter.com/barackobama>"
}
}
In practice, many teams use ORMs to bridge this gap. ORMs can help, but they also create new failure modes. (As examples, we discussed inefficient ORM-generated queries in How OpenAI Scaled PostgreSQL to Support 800 Million Users (Part 1), and the N+1 issue in What Is the Database N+1 Query Problem, and How Can You Avoid It?.)
That said, choosing relational or document storage should always come back to your specific use case. Also, this is no longer a strict either-or decision. Many relational databases now support document-like workflows (for example, JSON support in PostgreSQL and MySQL), and many document databases now support richer query patterns. Think of this as a spectrum, not a binary choice.
Do You Need Normalization?
Using IDs to avoid duplicating full records is generally called normalization. It reduces redundancy and can make writes cheaper. For example, storing only region_id in users avoids repeatedly writing full region data. The tradeoff is read complexity: you often need joins to assemble complete results.
By contrast, if you use a document database without normalization, writes can become heavier because each document may contain more data and consume more disk space. But reads can be simpler and faster when the document already matches what the application needs.
As we discussed in DDIA Ch1 Reading Guide — Tradeoffs in Data-Intensive System Design, this also maps to OLTP vs. OLAP patterns. OLTP workloads, with frequent writes and updates, often benefit from normalization. OLAP workloads are read-heavy, so denormalized structures can be a better fit.
Do You Need Schema Flexibility?
Another key question is how much schema flexibility you need. Relational databases enforce strict schemas. Document databases typically allow looser structure, often without strict database-level enforcement.
The book frames this as schema-on-write vs. schema-on-read, which is similar to static vs. dynamic typing in programming languages. Neither is universally better; each fits different constraints.
If your domain has stable structure and strict data quality requirements, schema-on-write is usually the better choice. In a banking system, for example, missing a required field can cause serious issues, so you want validation at write time and strong guarantees at the database boundary.
But if structure changes frequently or data sources are noisy, schema-on-read can be more practical. A common example is event logging and analytics tracking: event shapes evolve quickly, and forcing frequent schema migrations can create operational pain or downtime.
Do You Usually Read the Whole Record?
From a read-performance perspective, data locality also matters. Suppose your application usually needs an entire object at once, like rendering a full blog post page with title, date, full content, and section metadata. In that case, a document store can fetch the whole object in one read very efficiently.
{
"id": "blast-radius",
"title": "What is blast radius?",
"date": "March 10, 2026",
"content": "As system scale has grown in recent years... (thousands of words)",
"sections": [
{ "heading": "What is blast radius", "body": "..." },
{ "heading": "Isolation", "body": "..." },
{ "heading": "Redundancy", "body": "..." }
],
"tags": ["DevOps", "SRE", "System Design"],
"related_articles": ["feature-flags", "on-call", "monitoring"]
}
The downside is that if you only need a small subset of fields, many document-oriented access patterns still pull the full document, which can waste I/O and memory. Similarly, partial updates may still involve rewriting substantial portions of the document.
So if you choose a document model, confirm that your real access patterns actually benefit from whole-record reads, or group data by cohesion so fields that are usually accessed together are stored together.
Support ExplainThis
If you found this content helpful, please consider supporting our work with a one-time donation of whatever amount feels right to you through this Buy Me a Coffee page.
Creating in-depth technical content takes significant time. Your support helps us continue producing high-quality educational content accessible to everyone.