如何设计一个部署系统 Designing a Code Deployment System
2024年5月5日
本篇為部署平台 Zeabur 於 ExplainThis 的客座分享
比起许多系统设计的题目需要专门的知识 (例如即时共编需要懂 CRDTs 这类算法,或者邻近服务需要懂 Quad Tree),部署系统更需要对系统广度有所理解。要能有效设计一个能处理高并发,同时速度快的部署系统,需要对部署过程中发生哪些事情,有全盘的理解,才能针对各个面向做优化。
因此在工作坊最开始,Zeabur 团队先带大家回顾部署过程中会发生什么事。大家也可以先停下来想一想,今天当写完程式码,到让程式码被部署,会经过哪些流程?
直观初步想,如果要有一个可以自动部署程式的系统,我们约莫需要经过以下的流程。程式码推到远端的程式码存放处 (例如 GitHub),透过 Webhook 来通知部署系统的后端,后端根据最新的程式码进行建构。
这边要先停一下,当我们在提程式码建构时,要先回答一个问题“建构出什么东西可以被部署?”。大家不妨先停下来想一下,被面试官问这问题时,你会怎么回答?
以目前业界常见会部署的东西,大致可以分为以下几类:
- 静态档案 (static files)
- 容器映像档 (container image)
- 无服务函式 (serverless function)
- 以及一些针对不同语言的档案,例如 Java 有 JAR,或者用 Go、Rust 等语言可以部署二进制的档案
这时下一个问题来了,上面这些建构出来的东西,分别会被放到哪里? 因为总是需要放到某个地方,然后在我们绑定完域名 (bind domain) 后,客户端才可以访问到。大家不妨也思考一下,如果被面试官问到,你会怎么回答?
上面的前三种类别,分别会放在以下地方:
- 静态档案会放在 OSS (例如 AWS 的 S3)
- 容器映像档则会放在 Docker 或是用 Kubernetes 管理的多个节点
- 无服务函式则会放在 AWS Lamda 这类放无服务函式的地方
从部署平台的角度概览后,接着我们从使用者的角度来看。这边一样先来个常考的面试题目,当使用者在浏览器上输入 https://explainthis.io (或任何网址),接着会发生什么事?
假如只讨论大方向的话,一开始会有 DNS 解析,然后拿到 CNAME record,这个 CNAME record 会随着路由不断指向下一个 CNAME record,然后最终会指向某个 A record,也就是最终的 IP 位置。
而这个 IP 位置就会指向上面提到的,存放部署好的东西的位置。以静态档案来说,就会是指向某个 OSS,然后拿到部署好的内容后,让客户端可以造访。
假如把上面两段连在一起,就会是这样
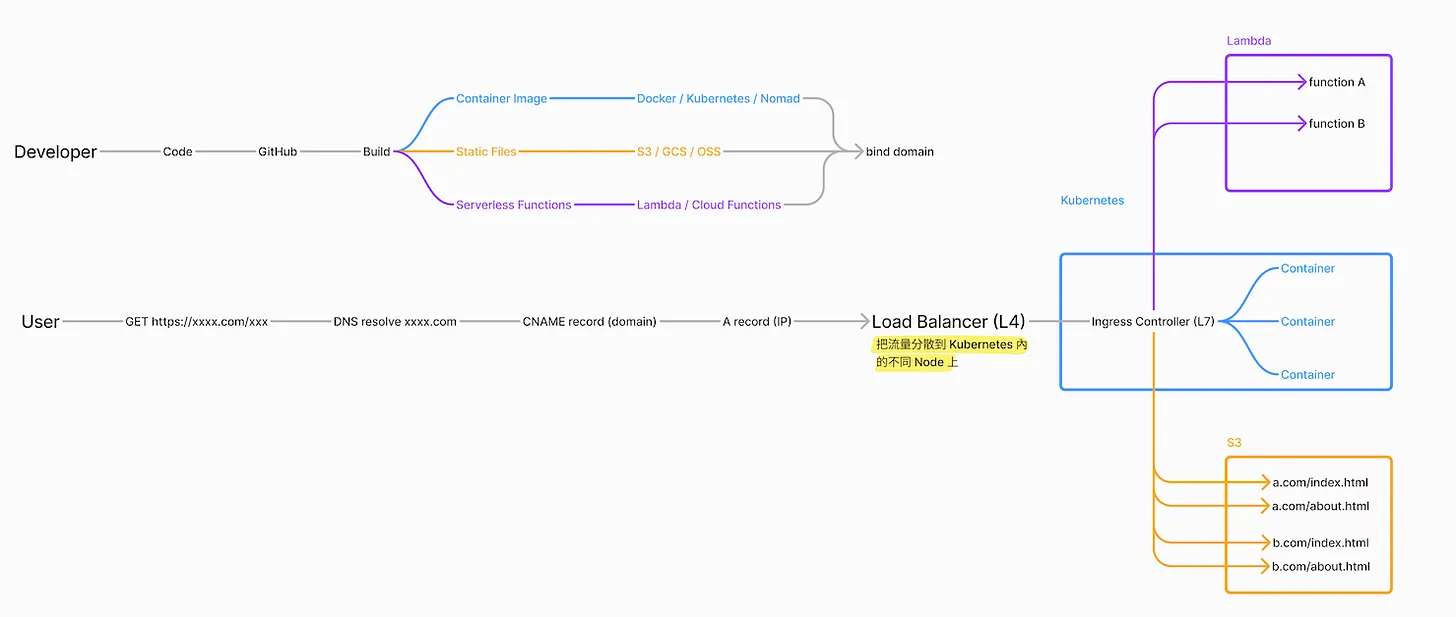
上面有提到,自动化部署平台,需要有侦测到程式码被推到远端程式码库的机制。一般来说会是透过 Webhook 来做到。Webhook 在做的事情就是当今天发生某件事,例如远端程式码更新,会触发某个通知,例如通知部署系统的后端,这时部署系统就可以进一步去做后面的操作。
具体来说,部署系统要能去分析要怎么用了什么程式语言、用了什么框架、版本是什么、有哪外部套件。因为如果能分析出来,就能够自动去建构。
这时问题来了,要如何知道用什么语言? 这其实很简单,不同的语言会有相对应不同的档案类型。举例来说,如果是 Node.js 可以去找 package.json 档案;或者如果是 Java 可以去找 pom.xml 或者 gradle.build。透过各个语言独有的档案,就能判断是用什么语言。而用什么框架,则是可以进一步去该语言的相关档案找,例如假如是用 Next.js,就可以在 package.json 里面找到使用 Next.js。
因为每个语言都有其对应的建构方式,所以当能够完成上面的分析,就有办法去做到自动化建构。举例来说,如果知道该专案使用 Node.js,那就可以用对应的 npm 来处理。这块 Zeabur 有一个开源专案叫 zbpack,处理了各种程式语言的解析到建构,这边我们先不展开细讲,推荐有兴趣的人可以去读原始码 (连结在此)开源专案可以做到。
如上面有提到的,当今天建构完,我们要进一步去部署。而静态档案与无服务函式会相对简单处理,因为静态档案可以直接呼叫 S3 的 API (或其他 OSS 的 API),而无服务函式则可以直接呼叫 Lamda 的 API,来完成部署。
但假如要处理容器的映像档,就有比较多要考量的。虽然说可以直接透过 Docker 来跑容器,但是如果今天要同时跑跑一千、一万、十万个容器,会需要好几台伺服器一起跑,就需要额外的解决方案。Kubernetes 是目前业界常用的方案,它可以帮忙把好几台伺服器合起,协助调度找到最适合的伺服器来跑。
总结目前为止提到的,从宏观的流程上来说,会像下面这样
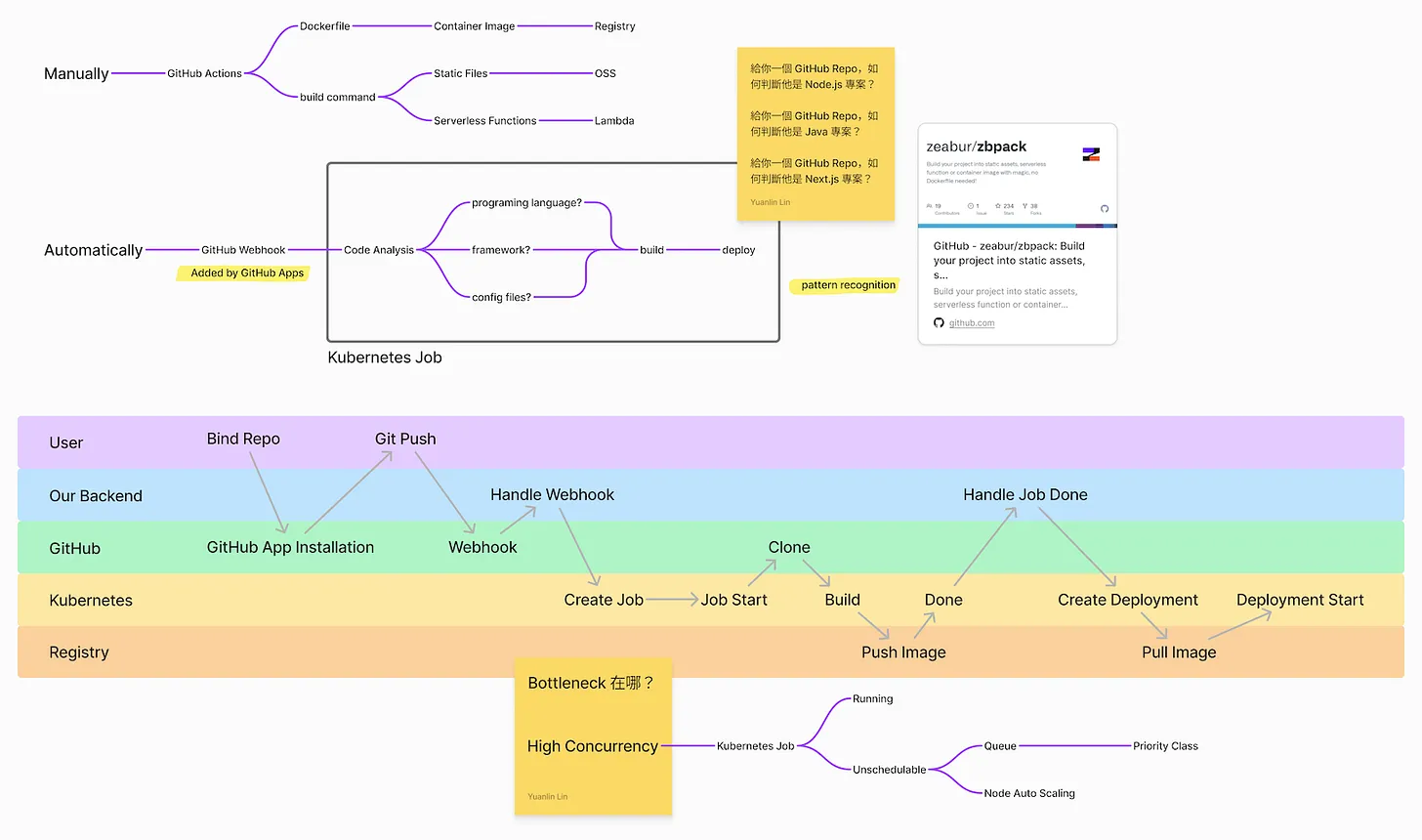
从上方的流程图可以看到,使用者绑定 GitHub 后,当把程式码推到 GitHub 后,GitHub 的 Webhook 会通知部署系统的后端。这时系统的后端透过 Kubernetes 的 Create Job (一个一次性的容器) 去执行分析与建构。建构完把映像档推到 Registry (可以理解成 Docker Hub)。
完成后,通知部署系统的后端,后端就可以去 Kubernetes 创建一个会一直跑的容器 (Create Deployment),这个容器会去 Registry 把映像档拉回来,然后让服务跑起来。
这时就有一个可以追问的面试问题。如果同时有成千上万的人要部署时,上面的那个部分,容易成为系统的瓶颈? 推荐大家可以先想一想。
一般来说,会是建构 (build) 到推送映像档 (Push Image) 这段。一般来说,建构一个前端可能是五分钟,建构一个 Go 的伺服器可能要两分钟,当流量一大,同时多个并发的任务,这段比较可能被卡住。
这也是为什么上面提到要用 Kubernetes,因为高并发时,后端可以同时开好几个 Job,Kubernetes 会去做容器调度,这时有些 Job 会跑起来,有些会是没办法被排程 (因为集群满了),要等到在正在跑的的跑完后,才会排下去跑。可以把这个设计理解成一个伫列 (queue),先进来的任务会先被处理,而处理端如果满了,还没被排程的任务就会在伫列中等,直到有多的机器有余力处理,才会在依序被排入。
不过在一个部署系统中,会加入更多的要素在。举例来说,会加入优先权 (priority),例如有些任务比较重要,会优先排到被处理 (像是付费使用者的任务可以被优先处理,直到有闲置运算资源才处理免费使用者)。又或者当想要更大量处理时,可以透过 Kubernetes 自动扩展 (auto scaling),同时开多个 Job 来加速。
以上我们基本走过了部署系统的整体架构,也谈了在这个架构下的瓶颈为何、要如何处理。在 Zeabur 团队的分享中,有进一步去谈可能会被深入追问的问题,例如当部署完成后,假如用 k8s 这类工具,因为同时会有多台机器,那该如何处理 IP 位置该指向哪里? 同时谈了设计全球多区域部署、如何从部署平台角度抵挡 DDoS 攻击。
这些更深入内容的文字整理,我们都放在 E+,该场直播的完整回放,也可以在 E+ 中看到。想要深入理解如何设计部署系统,欢迎加入 E+ (连结)。