什么是爆炸半径 (blast radius)? 如何有策略地缩减?
2026年5月9日
近几年随着系统规模越来越大、依赖关系越来越复杂,在后端系统设计,或者是 DevOps 与 SRE 相关领域的讨论中,爆炸半径 (blast radius) 变成经常被提到的词。
假如是在非软件工程领域的人,听到爆炸半径这个词的时候,直观会想到炸弹爆炸时的范围,但是在软件工程领域,爆炸半径是在指什么? 为什么对工程师来说这个议题重要? 有哪些常见方法可以降低事故的爆炸影响范围? 这篇主题文中,我们将会从 GitHub 的近期案例谈起,说明这个常听见的词与背后相关的议题。
什么是爆炸半径 (blast radius)?
在软件工程中,写程序只是其中一个环节,要确保软件在新增功能后,能稳定可靠地交付给用户,过程中还有其他需要顾及的面向。如果以阶段的角度来拆分,在前期可以通过测试等手段,来降低事故发生的可能性;在后期则可以通过回滚 (rollback) 等方式,加速系统回归稳定状态。
除了事故前与后之外,在事故发生时,降低影响范围也是软件团队应该关注的面向。在软件工程中,爆炸半径 (blast radius) 这个词,就是在谈论这个阶段。爆炸半径是指某一个事故发生时,被事故波及到的范围。
举例来说,假如今天某一个功能上线后才发现有 bug,如果这个 bug 只影响所在页面,那么爆炸半径就不算太大;不过有些事故的影响可能不只是单一页面,可能是横跨某个产品的多个页面,也可能是横跨多个产品。
以 GitHub 近期的事故为例,在 2026 年 4 月底 GitHub 接连发生两起事故。其中一起让部分 pull request 与 merge queue 的流程受到影响;另一起则是 Elasticsearch 子系统过载,导致 GitHub 上多个依赖搜索的体验出现问题,包含 pull requests、issues、projects 等页面的一部分搜索结果无法正常显示。从用户角度看,明明 Git 操作与 API 没有坏,但因为 UI 中有不少功能依赖搜索,最后仍造成显著干扰。
这正是爆炸半径过大的典型问题。当一个子系统没有被充分隔离时,它出问题后不会只停留在自己的边界内,而是通过隐性的依赖关系扩散到其他功能。GitHub 技术长 Vlad Fedorov 在《An update on GitHub availability》中也提到,GitHub 接下来的优先顺序会是可用性第一、容量第二、新功能第三,并且会通过降低隐性耦合、限缩爆炸半径,以及让系统在部分子系统承压时能优雅降级,来改善可靠性。
在近几年,有许多著名的事故,爆炸半径更是扩及到全世界。以 2025 年来说,让多数人印象最深刻的莫过于 Cloudflare 在 11 月的全球事故,该事故导致全世界一半以上的网站无法被浏览与使用,这种爆炸半径大到全世界的事故,是多数软件团队会竭尽所能避免的。
由于事故是无法避免的,即使有再完善的测试,现代软件系统往往有许多依赖,如果所依赖的组件出问题,即使自己团队的部分做得好,也难以避免事故。在 2024 年时,Azure 的 West US 区域的数据中心遇到重大停电问题,当时由于部署平台 Vercel 部分依赖 Azure 的服务,所以当 Azure 数据中心出事,即使 Vercel 这一端没有出任何错,也导致 Vercel 无法按预期使用 (链接)。甚至在 2026 年,因为战争的关系,AWS 在中东地区的数据中心被波及到,导致数据中心整个失火必须关闭。这种突如其来的意外是难以预期的。
在各种不可预期的事故下,软件团队不能只是把测试做好,而是要去思考问题发生时,可以如何避免事故扩散,以及思考如何确保使用软件产品的用户,不会因为技术端的事故而无法继续使用。换句话说,有效限缩爆炸半径是每个软件团队必须面对的挑战。
缩减爆炸半径的具体方法
在了解什么是爆炸半径后,相信多数读者会问「有哪些方法可以有效缩减爆炸半径?」,换句话说如果出现故障或事故,可以如何有效避免影响范围扩大?
全球规模的数据库平台 PlanetScale 在《The principles of extreme fault tolerance》一文中谈到他们使用的三大原则,分别是独立 (isolation)、冗余 (redundancy),以及静态稳定 (static stability)。以下让我们分别来看可以如何实践这三个原则。
独立隔离 (isolation)
当提到限缩爆炸半径,相信多数人第一时间会想到的是通过独立隔离的方式,让影响范围只会发生在特定的区域。
在软件业界,有许多公司的做法会是参考造船的过程。现代船只的设计,会为船设计舱壁 (bulkhead),把船体区分成多个船舱,使各个舱室彼此不会互通。在这种设计下,如果破洞发生时,水只会进到破损的那个舱室,不会影响到其他舱室;与此同时,当单一舱室进水时,其他舱室的结构能确保船体稳定,避免因为单一舱室进水而沉船。
把这个概念借用到软件工程,就是很常会听到的舱壁模式 (Bulkhead Pattern)。举例来说,微软的 Azure 就推荐架构师在设计架构时可以考虑舱壁模式 (链接),借此来把事故局部化。
有些派别会把舱壁模式称为细胞式架构 (Cell-based Architecture),之所以会这样命名,是将同一套系统复制成多个彼此隔离、各自完整的细胞单元,每个单元都能独立承载流量与状态;当某个单元失效时,影响只会局限在该单元,而不会拖垮整个系统。
回到 GitHub 的例子,GitHub 目前提到的改善方向也是把系统隔离做得更彻底,避免某个部分变慢或坏掉时拖垮其他部分。例如把 webhooks 迁移到独立的后端、把 git 与 GitHub Actions 这类关键服务从其他工作负载中隔离出来、降低单点故障,并把对性能与扩展需求较高的路径,从原本的 Ruby 单体加速拆到更适合这类工作负载的 Go 服务。这些做法本质上都是在降低耦合,让事故即使发生,也比较不会牵一发而动全身。
下图是来自 Azure 推荐的舱壁模式设计,通过把服务 A、B、C 分成三个互相独立的实体,假如今天服务 A 挂掉,爆炸半径就会被限缩在 A,不会影响到服务 B 与 C。
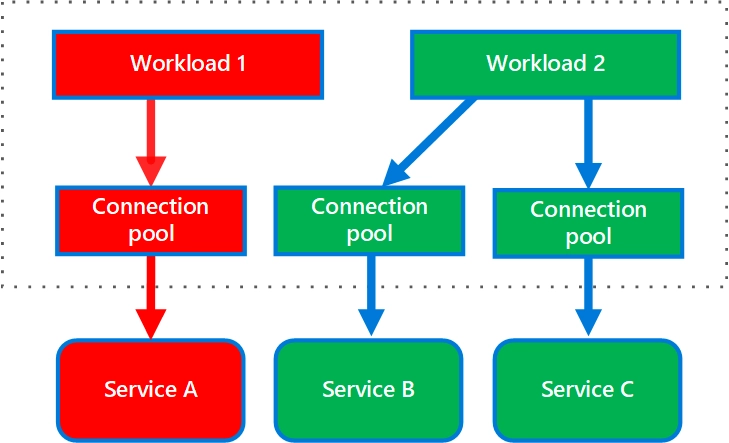
还记得上面有谈到,先前 Vercel 有演练当 Azure 的 West US 区域挂掉,要无缝迁移到 East US 区域,这边有的前提是 West US 区域挂掉不会影响到 East US 区域,这就要通过两者隔离才能做到。
事实上,不仅 Azure,各家云服务在架构上基本都是采取这种不共享 (shared nothing) 的架构,让单一地区的事故,仅会影响该地区。例如 AWS 在 2025 年有个 us-east-1 区域的事故,虽然该事故的影响范围不小 (因为很多公司把资源部署在该地区),但是当事故发生时,只有发生在该区域,没有扩及到 AWS 的其他区域。之所以能不扩及,正是因为先前 AWS 各区域的计算与存储都是独立的。
冗余 (redundancy)
前一段谈到的独立,背后意味着有冗余。所谓的冗余是指即使某些机器没有被使用,但从系统的角度会先把这些机器预备着,当出事故时可以立即切换到正在待命的机器,避免因为一个机器无法响应,就让整个系统无法运作。
冗余一般会搭配路由 (routing) 来使用,当今天主要依赖的组件出问题,可以通过路由迅速切换到在一旁待命的组件,在英文很常听到 failover 这个词就是在讲这件事。在业界,不少公司会通过定期的演练,来确保如果某个主要依赖出事故,切换到冗余的过程不会出问题。
Vercel 先前写过《Preparing for the worst: Our core database failover test》一文,谈他们如何具体做这件事,非常推荐一读。在文中有谈到,Vercel 之所以会开始做演练,正是前面谈到的 Azure West US 区域出事故时,即使当时 Vercel 有 East US 区域的冗余可用,但因为过往疏于演练,所以实际遇到故障时,没有很顺畅地切到 East US 区域的机器,该经验让 Vercel 的团队意识到平常演练的重要性,这样才能确保真的出事故时,不会手忙脚乱。
阅读更多
如果对限缩爆炸半径 (blast radius) 这个主题感兴趣,我们在 E+ 会员方案中的主题文有谈到更多具体实务的方法。对更深入了解这个主题,以及其他前后端开发、软件工程、AI 工程主题感兴趣的读者,欢迎加入 E+ 一起成长 (链接)。