什麼是 AI 的評估機制 (evals)?
2026年2月3日
在 AI 工程領域當中,評估 (eval) 幾乎是每個產品在開發週期時,不可或缺的環節。
傳統的軟體程式碼是確定的 (deterministic);換句話說,工程師可以僅看程式碼,就肯定輸入會有什麼對應的輸出;然而,由於 AI 模型的輸出是不確定性 (non-deterministic),當今天我們給定某個輸入後,沒辦法只看程式碼,就能確定 AI 會給出什麼輸出。
在這個前提下,傳統的軟體測試 (例如單元測試、整合測試、E2E 測試),將沒辦法百分百保證產出是否會如預期。
但是,在把 AI 加到軟體產品後,團隊仍需要判斷新加入的改動,是否有達到理想的成果;在這種狀況下,就需要有一個不同的機制,來確保跟 AI 部分有關的改動後,有讓產品變得更好。
在業界,這件事被叫 evals (來自 evaluations 的縮寫,中文直譯的話是評估機制,以下我們會以評估機制來代稱,但在業界可能更常會聽到大家直接說 evals)。
評估機制 (eval) 具體是什麼?
不過,具體來說「評估機制」是什麼呢? 假如要用一句話來描述,評估機制就像給 AI 端到端測試,根據預先定義的標準來評估輸出品質。
對於評估 AI 輸出來說,所謂的「正確」比傳統軟體的正確,有更多複雜的因素要考量。除了最基本的不能夠有客觀上可衡量的錯誤外,還有包含風格、遵照最佳實踐等不同的面向要評估。
先來看最基本的「客觀可衡量的錯誤」,先前在 ChatGPT 進到推理模型時代前,在論壇中經常可以看到這種客觀可衡量的錯誤。在下方截圖是當年在社群中比較多人討論的案例,大型語言模型不管怎麼問,都說草莓的英文 strawberry 中只有 2 個 r。

然而, strawberry 中客觀可數出 3 個 r。因此,從評估的角度,針對這個問題,AI 就無法順利通過。
接著來看牽涉主觀判斷的任務。舉例來說,假如是 AI 代理,今天請 AI 代理幫忙實作某個函式,例如某個叫 getUniqueValues 的效用函式,然後在 A 系統提示詞下 AI 生成了這個版本
const getUniqueValues = (arr) => [...new Set(arr)];
在改動系統提示詞後,AI 生成了這個版本
function getUniqueValues_v2(arr) {
const result = [];
for (let i = 0; i < arr.length; i++) {
if (result.indexOf(arr[i]) === -1) {
result.push(arr[i]);
}
}
return result;
}
哪一個版本是比較好的版本呢? 這其實沒有標準答案,假如把上面的問題,拿去問不同的工程師,可能會獲得不同的意見。有的可能會說第一種版本簡潔且用 Set 的效能比較好;但有人可能會說,第二種版本讓人比較容易讀,且容易放 debugger 追蹤過程。
因此,哪一個版本會被判斷為比較好的輸出,就仰賴產品與工程團隊去訂定的標準。
回到評估機制的定義,就是要先寫下這些標準,然後在有任何改動之後,把不同的輸入餵入,來看最終獲得的輸出,是否有達到期待,或者是不符合預期。
對此,如下面這張截圖提到,OpenAI 跟 Anthropic 的產品長,過去在訪談中都有提到,寫評估標準 (writing evals) 幾乎是開發 AI 產品時最重要的核心技能之一。

透過評估機制,避免決策是靠感覺
評估機制之所以重要,且被各大 AI 公司認為是核心技能,是因為評估機制是用來把關產品的品質的核心手段。
舉例來說,當今天某間 AI 模型商推出新的模型,是否要選擇採用? 要能夠回答這個問題,如果沒有評估機制,基本上很難回答。畢竟就算新的模型跑分很好看,實際整合到產品後,效果可能比前一代模型來得差 (例如當 GPT-5 剛推出時,非常多使用者在網路上詢問,可以如何退回 GPT-4o;這就說明跑分好不代表一切,在不同場景也可能有不同的結果)。
又或者假如今天團隊想要優化整體流程,例如透過更短的提示詞、更便宜的模型,來降低成本。但是不希望因為降低成本去影響品質,這時如果要能判斷不會影響到品質,就會需要有個評估機制來協助。
換句話說,如果沒有評估機制,就沒辦法知道新的改動是否比較好,也無法知道能不能進一步改善;決策變得只能靠感覺或猜測,這對於產品來說,是相當不理想的。
評估與傳統測試相似與差異處
除了能透過評估機制來協助決策,另一個評估機制的存在目的,是為了能有效把關產品的品質。當有了完整的評估機制,當有了某個改動後,可以在實際上線前先評估,確保上線後的版本不會比較差。
下圖是一個評估機制最核心的流程圖,假如仔細看,這個流程跟傳統開發會用的測試驅動開發 (TDD) 很類似 (不熟的讀者可以回顧 《TDD》一文),因此業界也有評估驅動開發 (evals-driven development,簡稱 EDD) 的說法。
簡單來說,EDD 就是先把評估的指標寫好,然後去調整產品 (例如更換模型、更換系統提示詞、更換呼叫的工具等等)。接著去跑評估,確保調整後的品質又更好;如果沒有的話,就要持續迭代直到通過評估為止。
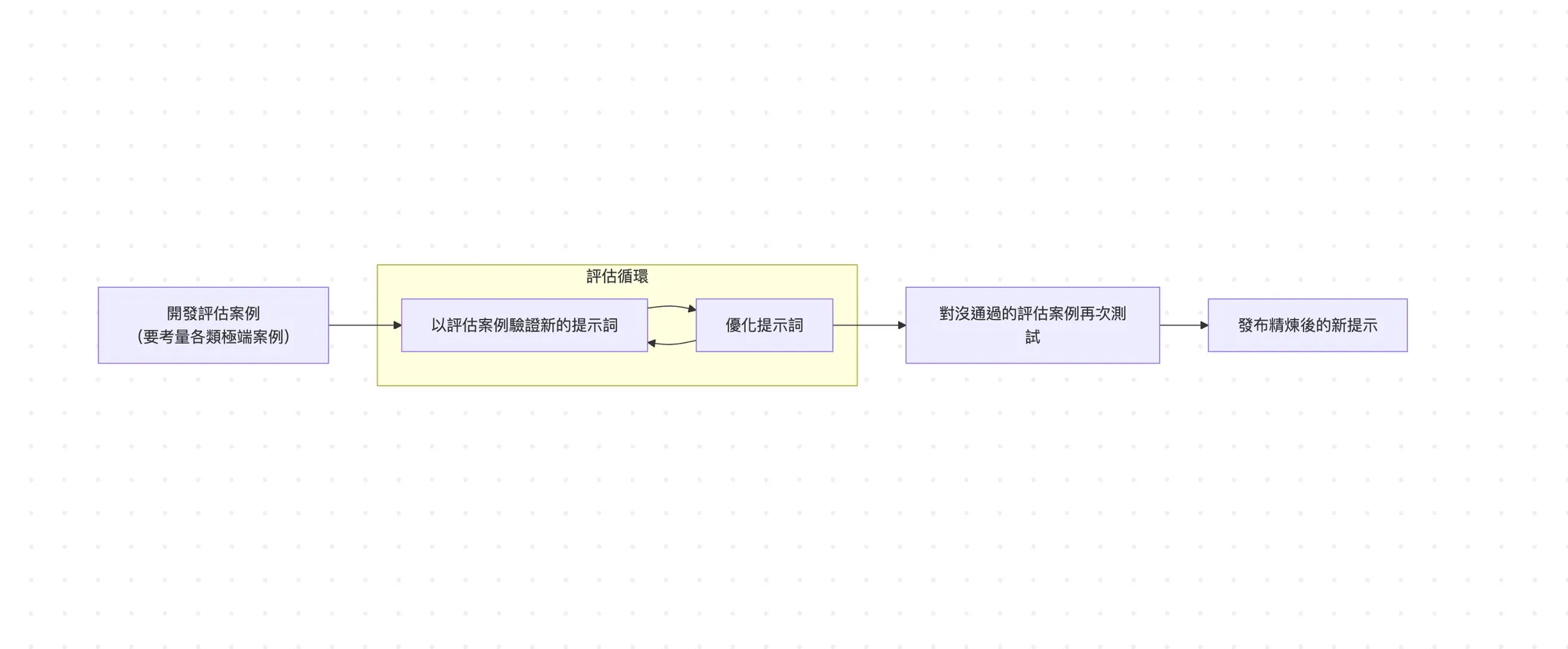
Anthropic 團隊的 Amanda Askell 曾經在一個貼文精闢地總結「一個好的系統提示詞的秘密,是測試驅動開發這個無聊但重要的方法。比起先寫下系統提示詞,然後測試該系統提示詞好不好,先寫下測試案例,然後找出能通過這些測試的系統提示詞」。

閱讀更多
如果對評估機制 (evals) 這個主題感興趣,想了解實務上做評估時可以如何做好,我們在 E+ 會員方案中的主題文有進一步談到。
對更深入了解這個主題,以及其他前後端開發、軟體工程、AI 工程主題感興趣的讀者,歡迎加入 E+ 一起成長 (連結)。