資料庫索引 (Database Index) 是什麼? 為什麼用 B+ tree?
2025年12月18日
在後端開發的日常中,開發者經常會跟資料庫索引 (database index) 打交道。也因此在後端的面試中,許多公司都很常會問「資料庫的索引是什麼? What is indexing?」這個問題。
在這篇文章中,我們會以 SQL 資料庫為例,來討論這個問題,不過在回答這個問題前,先讓我們透過一個情境來了解,為什麼需要索引?
沒有索引會有什麼問題?
假如今天有一張 Products 表,而使用者經常會根據價錢來搜尋產品,這時可能會寫 SELECT * FROM Products WHERE Price BETWEEN 100 AND 200 這樣的 SQL 語句。 在沒有特別做任何事情的狀況下,資料庫會掃過每一行,然後把符合 WHERE 條件的找出來。
這個概念就像線性搜尋一樣,當每多一筆資料,未來搜尋就會要多掃過一筆資料。這種 O(n) 式的搜尋,假如有一萬筆資料,就要掃過一萬行,假如有百萬筆資料,就要掃過百萬行。當資料庫的資料多起來,拿資料會顯得相對沒有效率。
上面提到,沒特別處理時,資料庫會用線性的方式掃過每一行,這樣很沒有效率。如果要有效率一點,該怎麼做呢? 相信這時你已經想到,就像我們在看書一樣,可以加上索引。
這邊找了一張 Google 「書本索引」出現的圖 (看起來是日本某個司法考試準備的教科書的索引),可以看到假如在沒有索引的狀況下,你要去找國稅通則法,會需要一頁頁翻找,就像上面提到的線性搜尋。然而,如果有了這個截圖的索引,就可以直接跳到 59 頁去找。
資料庫的索引也是類似的概念,當你創建了某個欄位的索引,資料庫在找資料時,就不再需用一行一行搜,而是可以更快速地到某個想搜的區域中,然後在該區域中搜尋,讓搜尋的速度變快很多。
什麼是索引?
在讀完上面的段落,相信大家有理解索引是在解決什麼問題。當你為資料庫創建適當的索引,將能讓你在做某些條件的搜尋時,變得更快速。這時回到這個常見的面試題,什麼是索引?
就像上面的日本司法考試教科書中的索引,是自己單獨一頁、有自己的結構 (例如民訴法放一起、民保法放一起),索引是一種資料結構,這個資料結構會複製原表中的部分資料,然後依據排序好的欄位,透過指標指回原本的表 (備註:透過指標,在索引這個資料結構,就不用存所有的資料,所需的空間就能減少)。
因此,當我們為上面這個例子 (SELECT * FROM Products WHERE Price BETWEEN 100 AND 200) 所在的表中的 Price 欄位新增索引,資料庫工具就會幫忙創建一個額外的資料結構。
CREATE INDEX idx_products_price ON Products(Price);
不過,在資料庫中,該用什麼樣的資料結構來加速搜尋呢?
相信提到能讓搜尋加速的資料結構,第一個會讓人想到的是二元搜尋樹 (binary search tree)。在一棵二元搜尋樹中,每個節點的鍵值都大於左子樹中所有節點的鍵值,且都小於其右子樹中所有節點的鍵值。以下面的例子,50 的左子樹的值都會是小於 50,而右子樹中的所有值都大於 50。
[50]
/ \
[30] [70]
/ \ / \
[20][40][60][80]
當資料結構這樣設計,在搜尋時就會快很多。假如要找到某個值,需要先與根節點比較;如果比根節點大,就往右子樹找,如果比根節點小,就往左子樹找。往其中一邊的子樹,就等於在搜尋時,完全不用管另一邊,等於面對的量就減半。
假如今天有百萬筆資料,第一次比較後就除去 50 萬筆,第二次比較再除去 25 萬筆,以此類推最多只要 20 次比較就能找到要找的值。從 Big O 的角度來看,原本掃過所有資料要 O(n),但假如改成用二元搜尋樹的資料結構,能讓搜尋變 O(logn)。
以上面的 Products 表為例,當我們為 Price 創建索引後,假如用二元搜尋樹的結構來排序好 Price ,接著再用類似二元搜尋 (binary search) 的樹狀搜尋,讓搜尋時間複雜度大幅降低。找到要找的價格後,再用搭配的指標,指回原本表當中的相對應的資料,這樣就能讓整體的搜尋加速許多。
上面我們談了以二元搜尋樹作為索引的資料結構,來加速搜尋。不過在實務上,多數關聯資料庫不是選用二元搜尋樹,而是用 B-tree 或 B+ tree 的資料結構。
為什麼選用 B-tree 或 B+ Tree?
在談 B-tree 之前,先讓我們一起來思考,假如我們想讓二元搜尋樹的搜尋變更快,可以如何改善?
前面談到,在有百萬筆資料的狀況下,把資料結構設計成二元搜尋樹,就不需要掃過百萬筆,而是只要讀取 20 次即可。有沒有可能透過某些方法,讓這個讀取的次數再往下降? 在 1971 年時,兩位電腦科學家 Rudolf Bayer and Edward M. McCreight 提出的 B-tree 就是一個能有效降低讀取次數的結構。
具體來說,B-tree 的一大特點是每一個節點都不只有一個鍵,而是有多個鍵。在 https://btree.app/ 這個網站中,可以實際動手建構 B-tree。下面是以「每個節點最多到 10 個鍵」為例,假如建構一個 1 到 100 的 B-tree 會有三層,所以搜尋最多只需要讀取三次。但假如在一個平衡的二元搜尋樹,100 個數會要至少七層。

假如今天有百萬筆資料,用二元搜尋樹來呈現的話,因為每個節點有兩個子節點,從數學上看 log₂(1000000),所以會有 20 層 。不過假如使用 B-tree,且每個節點如果有 100 個鍵,log₁₀₀(1000000) 則是會有 3 層。
對資料庫讀資料來說,在比較值與節點的大小,速度快到可以忽略不計。因此,假如每個節點有一百個鍵,要去比較某個值與鍵的值的大小,時間同樣快到可以忽略。但在需要進行磁碟 I/O 的情況下 (例如沒有命中快取時),讀取節點資料上,花的時間就無法忽略;假如讀取每個節點要花 10 毫秒,讀 3 個節點就會比讀 20 個節點,少掉 170 毫秒。
因此,對資料庫讀取來說,B-tree 讓每個節點帶有比較多的鍵,假如控制在一定數量下,不會帶來太多額外成本;同時,因為減少了讀取磁碟的 I/O 所需時間,所以比起二元搜尋樹,是個讓搜尋能更快完成的資料結構。
不過 B-tree 的設計,在某些情境下仍然會有效率不高的問題。舉例來說,假如要搜尋一段範圍,是上面的例子來說,假如在百萬筆資料中,要找價格在 1000 到 2000 之間的產品,在找價格 1000 的產品要讀磁碟三次,找 1001 的產品也要讀三次,一路到 2000 等於總共要讀 3000 次 (1000 x 3)。
前面提到,在資料庫查詢資料時,最花時間的部分之一是在讀磁碟中的資料這部分。推薦大家可以稍微暫停思考,在基於 B-tree 的資料結構下,有沒有辦法進一步調整,讓讀磁碟的動作變更少次?
B+ tree 這個基於 B-tree 改良的資料結構,就協助讓讀磁碟的操作變更少。在 https://bplustree.app/ 的網站中,能視覺化地創建 B+ tree,以下是我們創建的範例,大家可以先觀察一下 B+ tree 跟上面的 B-tree 在結構上有什麼差別。
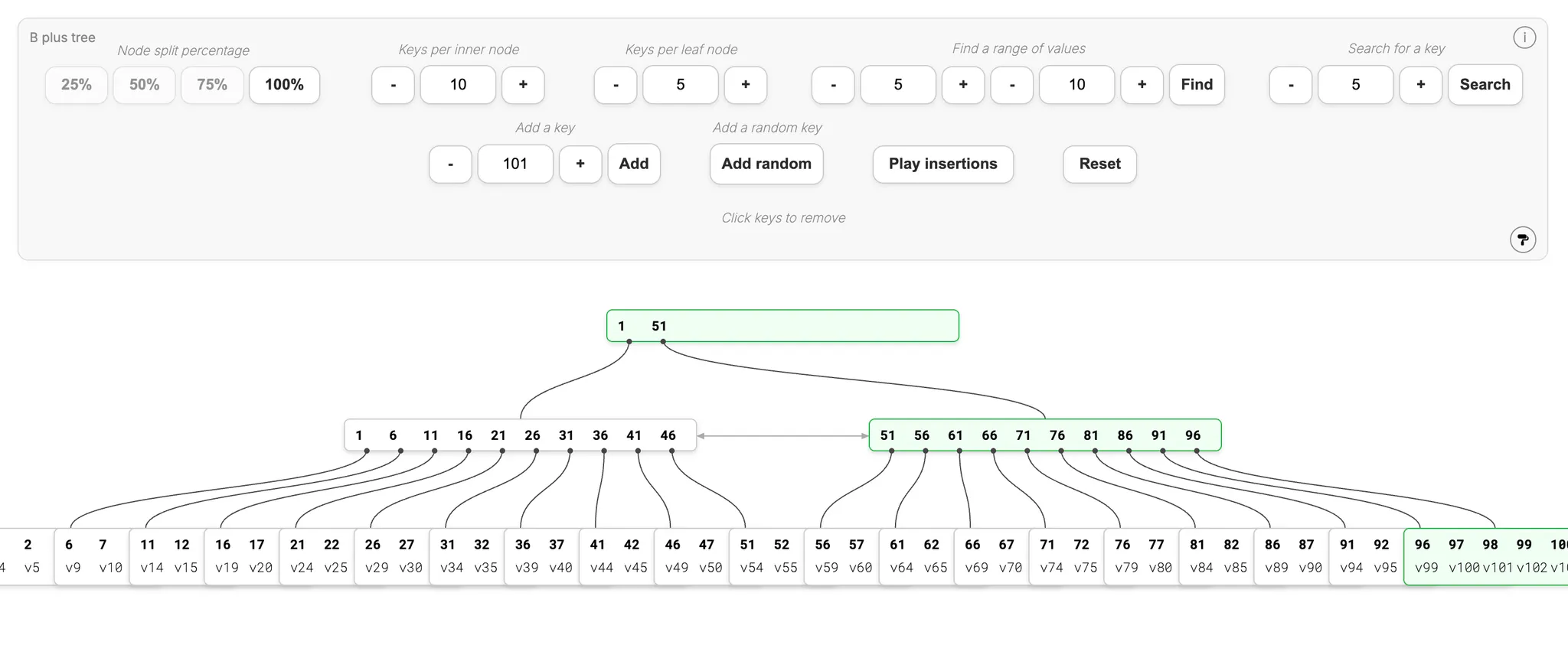
在上圖中可以看到,在 B+ tree 當中,在最底下的子節點外的節點都有重複出現,以 51 為例,在根節點、第二層的節點,以及最底下的葉節點 (leaf node) 都有出現。對比之下,在 B-tree 的結構中,每個值只會出現在一個節點,不會這樣重複出現。
這樣的設計是因為 B+ tree 把節點分成內部節點 (internal nodes) 與葉節點 (leaf nodes),內部節點只會作為指標 (pointer),指向最終的葉節點,具體的值只會在葉節點。因為內部節點通常容易快取,實際發生大量 I/O 的地方是葉節點,當這樣設計就能有效減少讀取磁碟,讓整體的速度更快。
除此之外,因為內部節點不存實際資料記錄,只存鍵值和指標,可以在相同空間的記憶體中存更多鍵,降低整體的樹高。如前面提到,樹的高度下降,就意味著需要磁碟讀取的次數會下降,用更少的磁碟讀取次數,完成相同的查詢。
閱讀更多
如果讀者們想更了解資料庫索引這個主題,包含在實務上應該選擇什麼欄位加入索引、索引使用的成本與取捨等,我們在 E+ 會員方案的主題文中,都有更詳細談。感興趣的讀者,可以在以下連結看到 E+ 的詳細介紹 (連結)。
本文為 E+ 會員方案的深度內容,截取段落開放免費閱讀。歡迎加入 E+ 會員方案,閱讀完整版本 (點此了解 E+ 的詳細介紹)。