什么是 AI 的评估机制 (evals)?
2026年2月3日
在 AI 工程领域当中,评估 (eval) 几乎是每个产品在开发周期时,不可或缺的环节。
传统的软件程序是确定的 (deterministic);换句话说,工程师可以仅看程序,就肯定输入会有什么对应的输出;然而,由于 AI 模型的输出是不确定性 (non-deterministic),当今天我们给定某个输入后,没办法只看程序,就能确定 AI 会给出什么输出。
在这个前提下,传统的软件测试 (例如单元测试、集成测试、E2E 测试),将没办法百分百保证产出是否会如预期。
但是,在把 AI 加到软件产品后,团队仍需要判断新加入的改动,是否有达到理想的成果;在这种状况下,就需要有一个不同的机制,来确保跟 AI 部分有关的改动后,有让产品变得更好。
在业界,这件事被叫 evals (来自 evaluations 的缩写,中文直译的话是评估机制,以下我们会以评估机制来代称,但在业界可能更常会听到大家直接说 evals)。
评估机制 (eval) 具体是什么?
不过,具体来说「评估机制」是什么呢? 假如要用一句话来描述,评估机制就像给 AI 端到端测试,根据预先定义的标准来评估输出品质。
对于评估 AI 输出来说,所谓的「正确」比传统软件的正确,有更多复杂的因素要考量。除了最基本的不能够有客观上可衡量的错误外,还有包含风格、遵照最佳实践等不同的面向要评估。
先来看最基本的「客观可衡量的错误」,先前在 ChatGPT 进到推理模型时代前,在论坛中经常可以看到这种客观可衡量的错误。在下方截图是当年在社群中比较多人讨论的案例,大型语言模型不管怎么问,都说草莓的英文 strawberry 中只有 2 个 r。

然而, strawberry 中客观可数出 3 个 r。因此,从评估的角度,针对这个问题,AI 就无法顺利通过。
接着来看牵涉主观判断的任务。举例来说,假如是 AI 代理,今天请 AI 代理帮忙实现某个函数,例如某个叫 getUniqueValues 的效用函数,然后在 A 系统提示词下 AI 生成了这个版本
const getUniqueValues = (arr) => [...new Set(arr)];
在改动系统提示词后,AI 生成了这个版本
function getUniqueValues_v2(arr) {
const result = [];
for (let i = 0; i < arr.length; i++) {
if (result.indexOf(arr[i]) === -1) {
result.push(arr[i]);
}
}
return result;
}
哪一个版本是比较好的版本呢? 这其实没有标准答案,假如把上面的问题,拿去问不同的工程师,可能会获得不同的意见。有的可能会说第一种版本简洁且用 Set 的性能比较好;但有人可能会说,第二种版本让人比较容易读,且容易放 debugger 追踪过程。
因此,哪一个版本会被判断为比较好的输出,就仰赖产品与工程团队去订定的标准。
回到评估机制的定义,就是要先写下这些标准,然后在有任何改动之后,把不同的输入喂入,来看最终获得的输出,是否有达到期待,或者是不符合预期。
对此,如下面这张截图提到,OpenAI 跟 Anthropic 的产品长,过去在访谈中都有提到,写评估标准 (writing evals) 几乎是开发 AI 产品时最重要的核心技能之一。

通过评估机制,避免决策是靠感觉
评估机制之所以重要,且被各大 AI 公司认为是核心技能,是因为评估机制是用来把关产品的品质的核心手段。
举例来说,当今天某间 AI 模型商推出新的模型,是否要选择采用? 要能够回答这个问题,如果没有评估机制,基本上很难回答。毕竟就算新的模型跑分很好看,实际整合到产品后,效果可能比前一代模型来得差 (例如当 GPT-5 刚推出时,非常多用户在网络上询问,可以如何退回 GPT-4o;这就说明跑分好不代表一切,在不同场景也可能有不同的结果)。
又或者假如今天团队想要优化整体流程,例如通过更短的提示词、更便宜的模型,来降低成本。但是不希望因为降低成本去影响品质,这时如果要能判断不会影响到品质,就会需要有个评估机制来协助。
换句话说,如果没有评估机制,就没办法知道新的改动是否比较好,也无法知道能不能进一步改善;决策变得只能靠感觉或猜测,这对于产品来说,是相当不理想的。
评估与传统测试相似与差异处
除了能通过评估机制来协助决策,另一个评估机制的存在目的,是为了能有效把关产品的品质。当有了完整的评估机制,当有了某个改动后,可以在实际上线前先评估,确保上线后的版本不会比较差。
下图是一个评估机制最核心的流程图,假如仔细看,这个流程跟传统开发会用的测试驱动开发 (TDD) 很类似 (不熟的读者可以回顾 《TDD》一文),因此业界也有评估驱动开发 (evals-driven development,简称 EDD) 的说法。
简单来说,EDD 就是先把评估的指标写好,然后去调整产品 (例如更换模型、更换系统提示词、更换呼叫的工具等等)。接着去跑评估,确保调整后的品质又更好;如果没有的话,就要持续迭代直到通过评估为止。
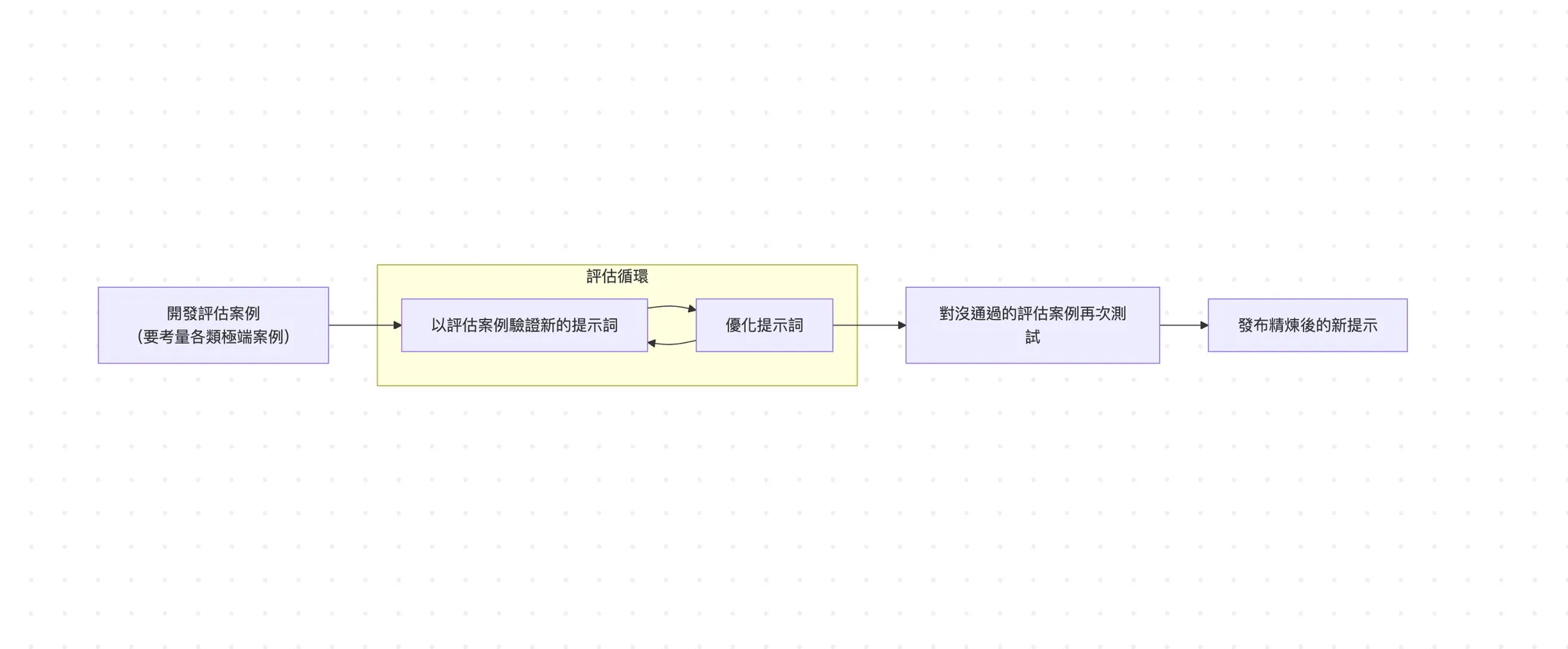
Anthropic 团队的 Amanda Askell 曾经在一个贴文精辟地总结「一个好的系统提示词的秘密,是测试驱动开发这个无聊但重要的方法。比起先写下系统提示词,然后测试该系统提示词好不好,先写下测试案例,然后找出能通过这些测试的系统提示词」。

阅读更多
如果对评估机制 (evals) 这个主题感兴趣,想了解实务上做评估时可以如何做好,我们在 E+ 会员方案中的主题文有进一步谈到。
对更深入了解这个主题,以及其他前后端开发、软件工程、AI 工程主题感兴趣的读者,欢迎加入 E+ 一起成长 (链接)。