DDIA 导读 CH3 — 数据模型与查询语言
2026年4月14日
在这一章中,作者重点讨论数据模型及其背后的查询语言。和任何软件系统一样,数据密集型应用也是由不同层级的抽象构建而成;每一层都需要相应的数据模型来表达。
例如,应用程序开发者会把现实世界中的不同对象(如组织、商品、资金)用不同的数据结构表示。在选择这些数据结构时,就会进入下一层:必须决定要用什么形式存储(例如 JSON 或 XML)。再往下一层,还要决定这些数据在内存或硬盘中如何表示。
在软件行业里,已经提出了很多不同的数据模型。理解这些模型及其优缺点,有助于做出更好的技术决策。在众多模型中,作者主要讨论三类:关系型(relational)、文档型(document)和图模型(graph)。
读到这里时,我们想到一个很常见的面试题:“请比较 SQL 与 NoSQL 的区别,并分析技术选型上的取舍。”这一章的内容,可以说是在深入回答这个问题(备注:NoSQL 类型很广,本章主要聚焦最热门的文档型与图模型 NoSQL,而不是覆盖所有类型)。
关系型 (Relational) vs. 文档型 (Document)
关系型数据模型中,最著名的就是 SQL。从上世纪 80 年代开始,SQL 至今仍被广泛用于各种应用程序。虽然 90 年代出现过对象数据库、21 世纪初出现过 XML 数据库,但这些最终都只是昙花一现。
到了 2010 年,NoSQL 这个词(Not Only SQL 的缩写)在社区中被大量讨论,成为新一轮试图挑战 SQL 主导地位的数据库浪潮。在众多 NoSQL 数据库里,至今仍有影响力的是文档型数据模型(社区中较热门的选择包括 MongoDB 与 Couchbase)。
关系模型的问题
要理解文档模型为什么受到关注,需要先回到 SQL 数据库的问题。正因为 SQL 数据库有一些对开发者不够友好的地方,社区才会持续探索其他方案。
对 SQL 的常见批评之一是:“如果用关系表存储数据,在应用程序代码中还需要写额外转换才能使用。”这就是所谓的不匹配(mismatch)。书中用 Obama 的 LinkedIn 页面为例,说明这种不匹配。
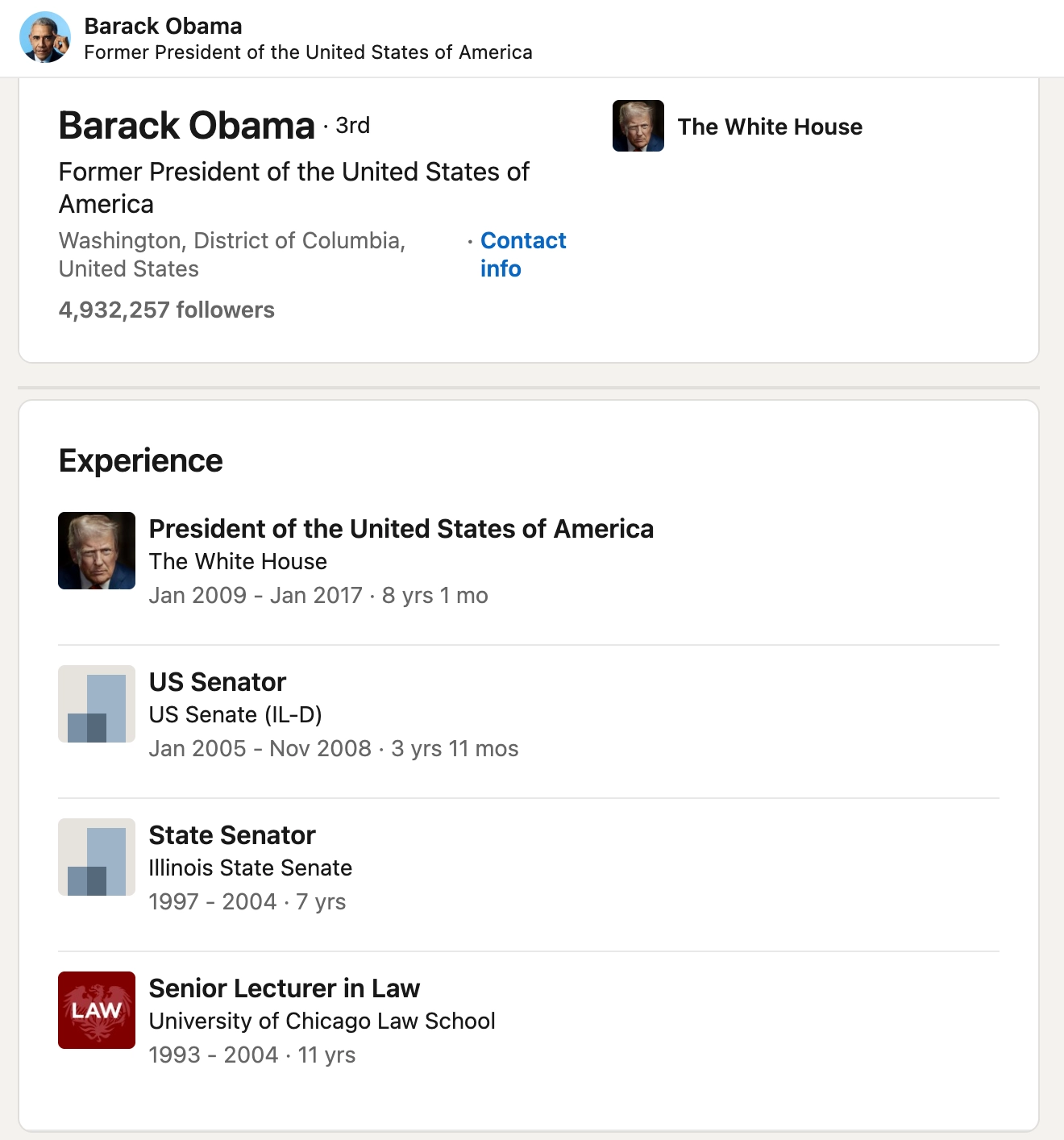
上图是 Obama 的 LinkedIn 截图。如果用 SQL 数据库,通常会拆成 users、regions、positions、education、contact_info 等不同表,再通过外键(foreign keys)把信息关联起来。
例如在用户表中,通常不会直接放完整地区信息,而是只放地区的 region_id,再通过 regions 表拿到完整地区信息。从程序设计角度看,这样做有助于解耦;但这也意味着对开发者来说,只拿到 id 并不够,还要写额外代码把它还原成人类可读的信息。
SELECT users.*, regions.region_name
FROM users
JOIN regions ON users.region_id = regions.id
WHERE users.id = 251;
相比之下,在文档数据库里,上述数据会直接存成类似下面这样的 JSON 对象。这个对象可以直接在应用层使用。换句话说,如果后端开发者要提供一个给前端调用的 API,可以直接从数据库拿到这个 JSON 对象,不需要在后端再写额外拼装逻辑,从查询角度也更直接。
{
"user_id": 251,
"first_name": "Barack",
"last_name": "Obama",
"headline": "Former President of the United States of America",
"region_id": "us:91",
"photo_url": "/p/7/000/253/05b/308dd6e.jpg",
"positions": [
{"job_title": "President", "organization": "United States of America"},
{"job_title": "US Senator (D-IL)", "organization": "United States Senate"}
],
"education": [
{"school_name": "Harvard University", "start": 1988, "end": 1991},
{"school_name": "Columbia University", "start": 1981, "end": 1983}
],
"contact_info": {
"website": "<https://barackobama.com>",
"twitter": "<https://twitter.com/barackobama>"
}
}
在业界里,开发者经常会用 ORM 来解决这种转换问题。但 ORM 也会带来额外问题(备注:我们在 OpenAI 如何将 PostgreSQL 扩展到支撑 8 亿名用户(上) 一文中提过 OpenAI 团队因 ORM 产生了低效查询;在 什么是数据库查询 N + 1 问题?如何有效避免? 一文也提过 ORM 使用不当很容易出现 N + 1 问题)。因此,在这类场景下,文档模型数据库能给开发者带来很大便利。
上面讲的是关系模型的问题,但在“关系型还是文档型”的选择上,仍要回到具体需求。尤其要注意:现在很多关系数据库已经支持文档数据库的一些优势(例如 PostgreSQL 和 MySQL 都支持存储 JSON 文档),而一些文档数据库也支持类似关系查询。因此,下面讨论的差异并非非黑即白,更推荐用“光谱”视角来理解。
是否需要规范化?
前面提到通过 id 避免重复存储完整数据,在业界通常称为规范化(normalization)。规范化可以减少冗余,让写入更轻(例如在 users 表里只存 region_id,不用写入整份地区信息);但读取会更慢一些(因为要写更多关联查询)。
相对地,如果用文档型数据库且不做规范化,通常意味着写入成本更高(因为数据体积更大,需要更多硬盘空间),但读取时不需要额外关联,速度会更快一点。因此,如果应用端使用的数据本来就接近文档结构,文档型数据库会是不错的选择。
还记得我们在 DDIA 导读 CH1 — 数据密集型系统设计的取舍 里谈过 OLTP 与 OLAP 的比较。对于 OLTP 来说,因为写入和更新更频繁,规范化在写入侧的优势通常更合适;而 OLAP 多数操作是读取,所以不做规范化的数据库往往更符合需求。
是否需要弹性?
另一个可思考的点是对弹性的需求。关系数据库有严格的 schema 检查;文档型数据库则提供更高弹性,通常不由数据库端强制执行。书中用写时模式(schema-on-write)与读时模式(schema-on-read)来描述这两种方式;这有点像编程语言中的静态类型检查与动态类型检查,两者各有适用场景,并不存在绝对优劣。
如果场景结构稳定、对数据质量和一致性要求高,写时模式(schema-on-write)更合适。例如在银行系统里,缺少某个字段就可能造成严重问题,这时就需要严格 schema 检查,在数据库层就保证数据质量,数据有误就不能写入,而不是等到应用层查询时才发现问题。
但如果场景结构变化频繁、数据来源不稳定,读时模式(schema-on-read)通常更合适。比如某些埋点日志追踪场景,事件类型多且变化快,很难用 schema 稳定管理;而如果每次变化都要做迁移(migration),频繁迁移可能导致数据库停机,对高变化场景非常不友好。
是否经常读取整份数据?
从读取角度看,还要同时考虑数据局部性(data locality)。例如,如果应用端所需数据刚好就是完整存放在文档数据库中的一份文档(如下例是一篇博客文章的数据),当读者打开页面时,网站需要标题、日期、全文、章节等内容一次渲染出来;这时文档数据库一次读取整份文档就能完成,效率很高。相对地,如果用关系数据库,数据被拆在多张表里,就需要多次查询,成本更高。
{
"id": "blast-radius",
"title": "什么是爆炸半径?",
"date": "2026年3月10日",
"content": "近几年随着系统规模越来越大...(全文数千字)",
"sections": [
{ "heading": "什么是爆炸半径", "body": "..." },
{ "heading": "独立隔离", "body": "..." },
{ "heading": "冗余", "body": "..." }
],
"tags": ["DevOps", "SRE", "系统设计"],
"related_articles": ["feature-flags", "on-call", "monitoring"]
}
但这种方式的另一面是:如果今天并不需要整份文档,而只需要其中一小部分,在文档数据库设计下通常仍会加载整份文档。为访问小部分数据却加载整份文档,会造成不必要浪费。同时,更新时即便只改一小段,也通常是整份文档更新。因此,如果要选择文档数据库,需要确认使用场景确实常常读取整份数据,或根据内聚性把会一起使用的数据放在一起,才能更好发挥其性能优势。