DDIA 导读 CH4 — 存储与检索
2026年5月10日
在 DDIA 导读 CH3 — 数据模型与查询语言 当中,作者聚焦讨论不同模型的数据库;到了这一章,作者进一步讨论数据库如何存数据,以及用户向数据库取数据时,数据库会如何返回数据。
这两个问题也是任何数据库的根本。如果要实现一个最简单的数据库,下面这个 Bash 函数能够通过 set 来存某个值,并通过 get 来拿被存入的值,基本上已经满足了数据库的最小需求。
#!/bin/bash
db_set () {
echo "$1,$2" >> database
}
db_get () {
grep "^$1," database | sed -e "s/^$1,//" | tail -n 1
}
当然,在实务上不太会用这种简易版本,因为很明显,一旦数据量变大,这种实现方式下的 db_get 性能会很差。每次要找某一条数据,db_get 都需要从头到尾扫过整个数据库文件,才能找到对应的键(key)。从时间复杂度看,这是 O(n),所以数据量翻倍,查询时间也会翻倍。
读者觉得可以通过什么方法加速、解决这个问题呢?多数读者应该都会想到索引(index)。事实上,我们在 数据库索引(database index)是什么?如何选择加在哪个字段上? 这篇文章里已经讨论过索引,不过在这本书中,作者从更底层的角度来讨论索引,下面一起来看。
索引(index)
如前文所述,数据库索引是一种额外的数据结构。新增或删除索引时,不会改变数据库本身的数据内容。索引主要影响两件事:一是查询可以更快;二是由于要维护额外结构,会占用更多空间,也会提高写入成本(因为写入时需要同步更新索引)。所以是否要加索引,依然是数据库使用者需要权衡的选择。
哈希索引(hash indexes)
建立索引最简单直观的方法,是从键值对开始。比如可以用一个哈希表(hash map)来实现简易索引。数据库写入新数据的同时,在内存里同步更新哈希表,表中的键映射到磁盘中的某个位置。这样在磁盘中查找某条数据时,就不必扫描整个文件,而是可以直接跳到数据所在位置。
但这种做法也有明显限制:第一,键不断增加后,内存最终会被占满;第二,因为索引在内存中,机器重启后会丢失,必须重新扫描磁盘重建。另外,哈希分布本身是无序的,做范围查询时无法利用顺序性,效率会比较差。
SSTable
由于上述问题,哈希表很少单独作为数据库索引的核心方案。更常见的方式,是让键按顺序排列而不是随机分布。SSTable(Sorted String Table)就是一种按键排序的实现方式。
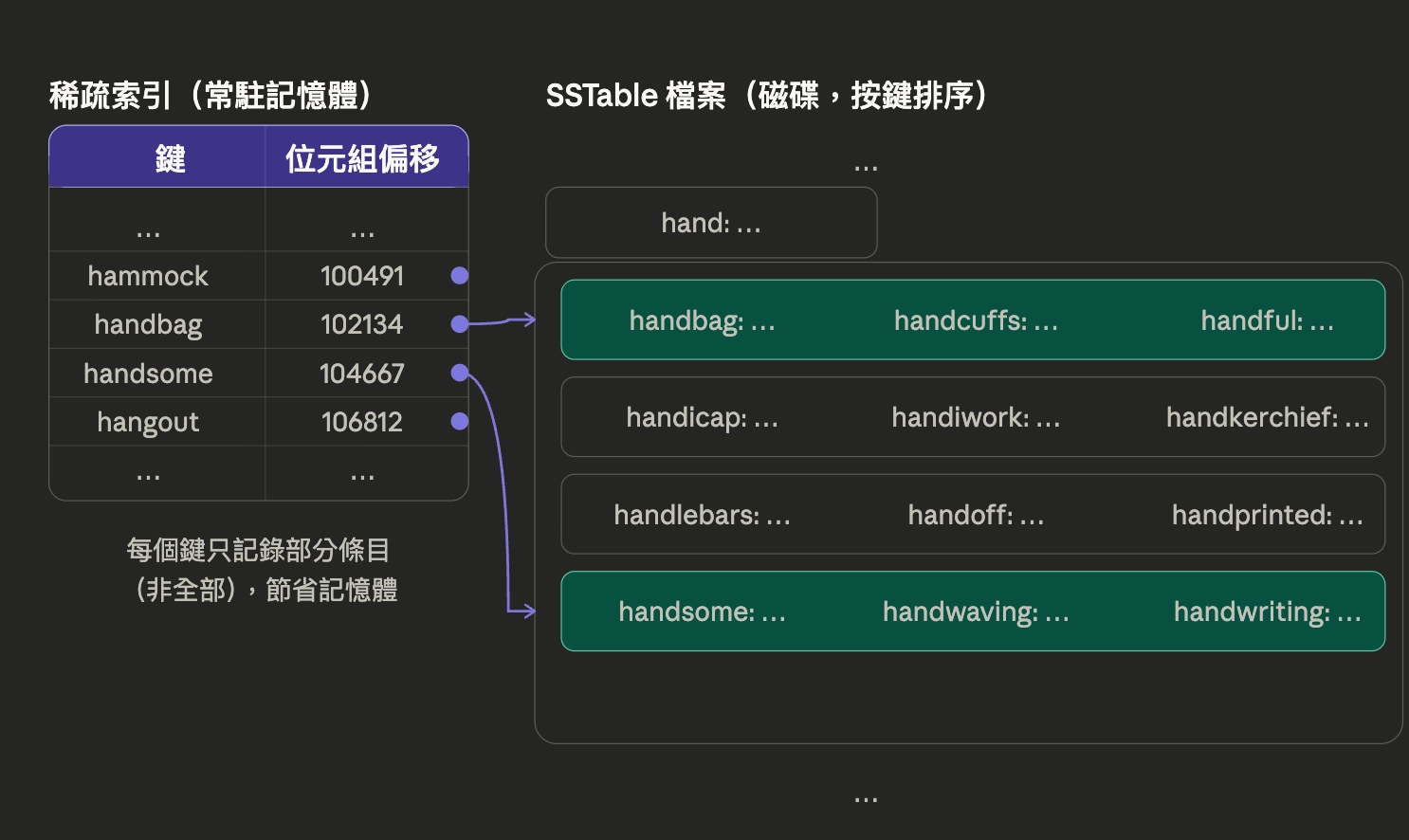
从上图可以看到,SSTable 有三项关键改进:
- 降低内存占用:通过稀疏索引(sparse index)把索引按块管理。比如第一块键是
handbag,第二块是handsome。当在内存中查找handiwork时,虽然它不在索引表里,但因为它的偏移量位于handbag与handsome之间,就可以定位到handbag这块再查找。这样能显著减少需要常驻内存的键数量。 - 提升范围查询效率:如果用纯哈希来查
handsome与hello之间的词,由于分布是随机的,没有顺序可利用,只能做全表扫描,效率不高。SSTable 分块且有序,可以直接定位到相关区块,效率高得多。 - 压缩以减少磁盘空间与 I/O 带宽:因为 SSTable 的键有局部顺序,不像哈希表那样完全随机,可以用 LZ4 等算法压缩具有共同前缀的字符串(比如
handbag、handcuffs、handful、handicap都有hand前缀),从而减少磁盘占用并降低 I/O 带宽压力。
不过,纯 SSTable 虽然在查询上有优势,写入成本会更高。比如要在上面的 SSTable 中写入 "handlebars",磁盘文件不能像数组那样中间插入一格,只能重写整个文件。如果文件很大,为了插入一个键就要重写大量数据,从扩展性上并不理想。
因此,业界通常会搭配内存表(memtable),先在内存中完成排序。写入磁盘时已经是有序数据,可以顺序追加写入,不需要做中间插入,速度会比随机写快很多。删除某个键时,则通过另一张记录表(tombstone)标记该键已删除,在后续合并阶段再真正清理。
这种方式通常被称为 LSM。LS 是 Log-Structured,表示写入以追加为主,先排好顺序再写新文件,而不是在旧文件中间插入;M 是 Merge,表示更新或删除通过 tombstone 记录,并在合并时只保留同一键的最新值。
布隆过滤器(Bloom Filter)
上面提到的 SSTable 与 LSM 已经带来很大改进,但如果读取一个不存在的键,效率仍不理想,因为需要先查内存表,再逐层查多个 SSTable,才能确认该键不存在。因此,实际实现中通常会搭配额外的布隆过滤器(Bloom Filter),先判断某个键是否可能存在,从而为不存在的键省掉大量不必要的磁盘读取。

从图中可以看到,布隆过滤器是一个位数组(bit array)。写入 SSTable 时,对每个键执行 k 个哈希函数,把结果对应的位置设为 1。比如 "handbag" 把位 2、4、9 设为 1,"handoff" 把位 5、9、15 设为 1。
查询 "handheld" 时,同样执行哈希函数,得到位 6、11、2。此时只要任意一位为 0,就可以确定这个键从未被插入,因为插入时会把所有对应位都设为 1。既然位 6 = 0,就可以直接跳过,无需读取磁盘。
通过这个额外数据结构,我们能在不扫描整个 SSTable 的情况下快速判断某些键不存在。相比 SSTable 本体,布隆过滤器占用空间很小,所以这是典型的“用小空间换时间”的优化策略。
B 树
前面作者介绍了 LSM 树方案,但在业界中另一个更主流的索引结构是 B 树。我们之前在《数据库索引(database index)是什么?如何选择加在哪个字段上?》一文中已经详细讨论过 B 树与 B+ 树,这里不再展开,重点看作者对 LSM 树和 B 树的比较。
LSM 树相对 B 树的优势在于:写入时不需要覆盖整页,整体磁盘使用效率更高;同时写入 I/O 主要是顺序写(而 B 树更多随机写),因此吞吐通常更高。如果业务更偏写多读少,LSM 往往更合适。
B 树相对 LSM 树的优势在于:层级通常更少,读取速度更稳定;LSM 查询可能需要读取多个 SSTable,虽然可借助布隆过滤器优化部分场景,但整体稳定性通常不如 B 树。另外,B 树本身有序,范围查询可以直接顺序扫描,不需要像 LSM 那样跨多来源合并,整体效率更高。因此在读多写少场景下,B 树通常更合适。
阅读更多
除了上面提到的内容,DDIA 第四章还讨论了更多类型的索引比较。如果你对完整 DDIA 第四章导读感兴趣,我们在 E+ 会员方案 的主题文中有完整版。若你希望深入学习这个主题,以及其他前后端开发、软件工程、AI 工程主题,欢迎加入 E+ 一起成长(链接)。