DDIA 導讀 CH3 — 資料模型與查詢語言
2026年4月14日
在這一個章節中,作者著重探討資料模型與背後的查詢語言。如同任何軟體一樣,資料密集型應用是由不同層級的抽象所建構而成;每一層都需要有相對應的資料模型來表示。
舉例來說,應用程式的開發者,會把現實中的不同對象 (例如組織、貨品、資金),用不同的資料結構來呈現。在選擇這些資料結構的同時,就會進到下一層,必須面對要選擇用什麼形式來存 (例如用 JSON 或 XML)。如果要再往下一層,又需要決定在記憶體或磁碟中,該如何呈現這些資料。
在軟體業界中,已經有非常多不同的資料模型被提出,懂得這些不同的模型,以及其優缺點,將有助於做出更好的技術決策。在眾多資料模型中,作者主要探討三種資料模型,包含關係型 (relational)、文件型 (document),以及圖型 (graph)。
在讀這篇文章時,讓我們想到一個過去很常見的面試問題「請比較 SQL 與 NoSQL 的區別,並分析技術選擇上的取捨」。這個章節的內容,可以說是深入地回答這個問題 (備註:NoSQL 的類型很廣,這章主要專注在最熱門的文件型與圖型 NoSQL,而非所有類型)。
關係型 (Relational) vs. 文件型 (Document)
關係型的資料模型,最著名的非 SQL 莫屬,從上個世紀的 80 年代開始,SQL 至今仍廣泛被運用在各種不同的應用程式中。雖然在 90 年代有物件資料庫、二十一世紀初期有 XML 資料庫出現,但這些資料庫最終都僅是曇花一現。
到了 2010 年,NoSQL 這個詞 (Not Only SQL 的簡寫) 在社群中被大量討論,成為新一輪試圖推翻 SQL 統治地位的資料庫。在眾多 NoSQL 資料庫中,至今仍有影響力的是文件型的資料模型 (在社群中,比較熱門的選項包含 MongoDB 與 Couchbase)。
關係型模型的問題
要了解文件型模型為什麼會得到關注,需要先回到 SQL 資料庫的問題。因為 SQL 資料庫有某些對於開發者來說,比較不那麼方便的地方,所以社群才會探索其他解決方案。
SQL 的常見批評之一是「如果用關係表來存資料,在應用程式的程式碼中,還需要寫額外的轉換才能用」,這種不匹配 (mismatch)。書中舉了 Obama 的 LinkedIn 頁面為例,來說明這種不匹配的狀況。
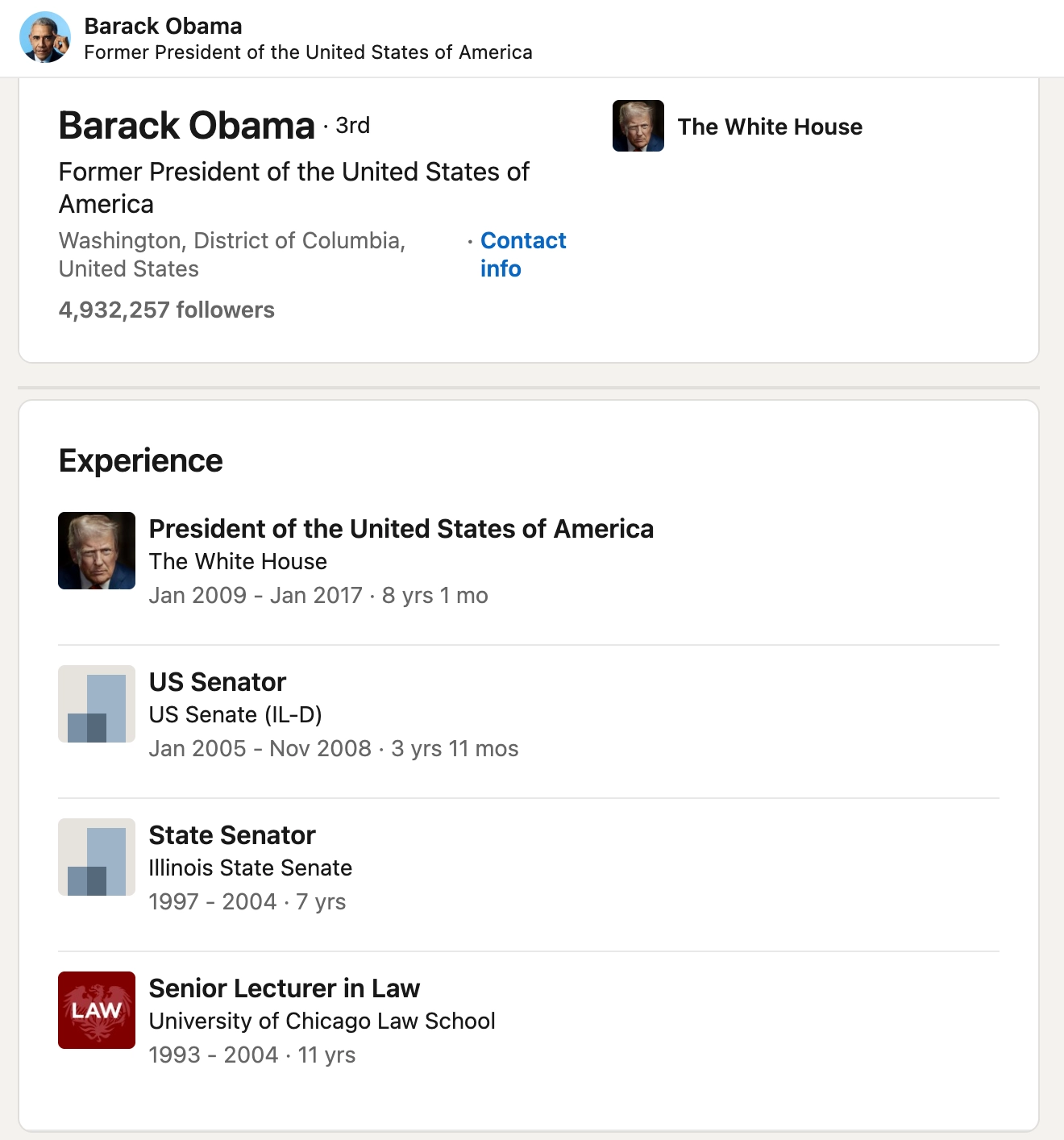
上圖是 Obama 的 LinkedIn 截圖,如果用 SQL 資料庫,通常會拆成 users、regions、positions、education、contact_info 等不同表,然後透過外鍵 (foreign keys) 來把資訊連在一起。
舉例來說,在使用者的表當中,通常不會放完整的區域資訊,只會放區域的 region_id,然後透過 regions 的表來拿到完整區域資訊。從程式設計的角度,這樣的優勢是能夠有效解耦合,只是這也意味對於人類開發者來說,只拿到 id 沒有用,還需要寫額外的程式碼來拿人類可讀懂的資訊。
SELECT users.*, regions.region_name
FROM users
JOIN regions ON users.region_id = regions.id
WHERE users.id = 251;
相比之下,在文件資料庫中,上述的資料會直接存成以下形式,類似於一個 JSON 物件。這個 JSON 物件可以直接在應用層被用。換句話說,假如一個後端開發者,要開一支 API 給前端呼叫,可以直接從資料庫拿到這個 JSON 物件,不用在後端程式碼多寫程式碼處理,從查詢的角度來看更簡單。
{
"user_id": 251,
"first_name": "Barack",
"last_name": "Obama",
"headline": "Former President of the United States of America",
"region_id": "us:91",
"photo_url": "/p/7/000/253/05b/308dd6e.jpg",
"positions": [
{"job_title": "President", "organization": "United States of America"},
{"job_title": "US Senator (D-IL)", "organization": "United States Senate"}
],
"education": [
{"school_name": "Harvard University", "start": 1988, "end": 1991},
{"school_name": "Columbia University", "start": 1981, "end": 1983}
],
"contact_info": {
"website": "<https://barackobama.com>",
"twitter": "<https://twitter.com/barackobama>"
}
}
在業界中,很常看到開發者會用 ORM 來解決這種轉換。不過 ORM 又會造成額外的問題 (備註,我們在 OpenAI 如何將 PostgreSQL 擴展到支撐 8 億名使用者 (上) 一文談過 OpenAI 團隊用 ORM 導致有效率很差的查詢;在 什麼是資料庫查詢 N + 1 問題? 如何有效避免? 一文也談過用 ORM 很沒寫好就會出現 N + 1 問題)。也因此,文件模型的資料庫在這種情境下,能為開發者帶來很大的便利。
上面談到了關係型模型的問題,但在選擇關係型還是文件型這點上,仍需回到當下的需求。特別注意,由於現在許多關係資料庫會支援文件資料庫的優點 (例如 PostgreSQL 與 MySQL 都已經有支援存 JSON 文件),或是文件資料庫有支援類似關係的查詢,所以下方談的點不是完全非黑即白,更推薦從光譜的角度來看。
是否需要正規化?
以上面提到透過 id 來省去重複存完整資料,在業界通常會用正規化 (normalization) 這個詞來描述。正規化能減少冗余讓寫入更快 (例如在 users 表中只需要放 region_id 而不用寫入所有區域相關資訊),但是讀取上會比較慢 (因為需要多寫關聯來拿資料)。
相較之下,如果用文件型的資料庫,沒有做正規化,就意味著在多數狀況寫入的成本更高 (因為要存的資料變多,需要更多硬碟空間),但是讀取上不用額外寫關聯,會比較快一點。因此,假如應用端使用的資料直接類似文件型存的資料,那用文件型的資料庫會是不錯的選擇。
還記得在 DDIA 導讀 CH1 — 資料密集型系統設計的取捨 有談到關於 OLTP 與 OLAP 的比較,對於 OLTP 來說,因為寫入與更新比較頻繁,正規化在寫入的優勢就會比較適合;而 OLAP 則因為絕多數的操作是讀取,所以用沒有做正規化的資料庫,會更符合需求。
是否需要彈性?
另一個可以思考的點是對於彈性的需求。關係型的資料庫有嚴格的 schema 檢查;而文件型則是提供比較大的彈性,通常不由資料庫端強制執行。書中用寫時模式 (schema-on-write) 與讀時模式 (schema-on-read) 分別描述這兩種狀況;這類似程式語言中的靜態型別檢查與動態型別檢查,兩者有適切的地方,沒有哪個絕對的好。
如果是在結構固定、對資料品質與一致性要求高的情境下,用寫時模式 (schema-on-write) 會更適合。舉例來說,在銀行系統,如果少了某個欄位可能導致大問題的狀況,就需要有嚴格的 schema 檢查,在資料庫這一層就確保資料的品質,資料有錯就不能寫入,而不是等到要查詢實在應用層才檢查。
不過如果在結構常常變化、資料來源不穩定的情況,讀時模式 (schema-on-read) 則會比較適合。舉例來說,在一些埋 log 做追蹤的情境,因為追的事件種類多且可能頻繁變化,難以用 schema 管理,且用 schema 管理就需要在變更時做遷移,而太頻繁做遷移 (migration) 讓資料庫得停機,對於這種變化度高的場景很不友善。
是否常常讀整份資料?
從讀的角度來看,資料區域性 (data locality) 也需要同時考慮。舉例來說,如果今天在應用端要的資料,是剛好整份存在文件資料庫 (例如下方這個範例,是一篇部落格文章所需的內容),當讀者打開這篇文章頁面,網站需要標題、日期、全文、章節等一次性把全部內容渲染出來;這時文件資料庫一次讀取整份文件就能完成,效率很高。反之,如果用關係資料庫,因為資料被拆成多張表,就需要有多次查詢,花比較多時間。
{
"id": "blast-radius",
"title": "什麼是爆炸半徑?",
"date": "2026年3月10日",
"content": "近幾年隨著系統規模越來越大...(全文數千字)",
"sections": [
{ "heading": "什麼是爆炸半徑", "body": "..." },
{ "heading": "獨立隔離", "body": "..." },
{ "heading": "冗餘", "body": "..." }
],
"tags": ["DevOps", "SRE", "系統設計"],
"related_articles": ["feature-flags", "on-call", "monitoring"]
}
但這種方式的反面刃在於,如果今天不是要一次渲染整個文件,而是只要部分資料,在文件資料庫的設計下,仍通常會載入整個文件。存取一小部分卻要載入整個文件,會造成不必要的浪費。與此同時,在更新時即使只更新部分,也通常會是整份文件的更新。因此,如果要選擇用文件資料庫,確保使用情境是讀整份資料,或根據內聚性把會一起用到的資料放一起,會比較能發揮其效能優勢。
閱讀更多
除了上面提到的點,在 DDIA 第三章,作者還談到了圖型資料庫的比較,如果你對完整 DDIA 第三章的導讀感興趣,我們在 E+ 會員方案中的主題文,有完整的版本。對更深入了解這個主題,以及其他前後端開發、軟體工程、AI 工程主題感興趣的讀者,歡迎加入 E+ 一起成長 (連結)。