DDIA 導讀 CH4 — 儲存與檢索
2026年5月10日
在 DDIA 導讀 CH3 — 資料模型與查詢語言 當中,作者聚焦討論不同模型的資料庫,而到了這一章,作者進一步談資料庫如何存資料,以及使用者跟資料庫拿資料時,資料庫會如何回傳資料。
這兩個問題也是任何資料庫的根本。如果要實作一個最簡單的資料庫,下面這個 Bash 函式能夠透過 set 來存某個值,以及透過get 來拿被存入的值,基本上已經滿足了資料庫的基本所需。
#!/bin/bash
db_set () {
echo "$1,$2" >> database
}
db_get () {
grep "^$1," database | sed -e "s/^$1,//" | tail -n 1
}
當然,在實務上不太會用這種簡易的版本,因為顯而易見地,如果資料量一大起來,這個實作方式下的 db_get 效能會很差。每當想要找某一筆資料,db_get 都需要從頭到尾掃過整個資料庫,來找到對應的鍵 (key)。從時間複雜度的角度來看,這是 O(n),所以資料量加倍,搜尋時間也會加倍。
讀者們覺得可以透過什麼方法加速,來解決這個問題呢? 相信多數讀者都會想到索引 (index) 這個概念。事實上,我們在 資料庫索引 (database index) 是什麼? 如何選擇加在哪個欄位上? 主題文曾經談過索引,不過在這本書中,作者從更根本的角度來討論索引,以下讓我們一起來了解。
索引 (index)
如先前在 資料庫索引 (database index) 是什麼? 如何選擇加在哪個欄位上? 主題文談過的,資料庫索引是一個額外的資料結構,在新增與刪除索引時,不會影響到資料庫本身的內容。索引會影響的主要有兩點,一點是在查詢時能夠協助加速;另一點則是因為要維護額外的資料結構,會佔據更多空間,也會讓寫入時的成本增加 (因為要更新索引,所以寫入會變慢)。因此,是否要加索引,需要資料庫使用者的取捨判斷。
雜湊索引 (hash indexes)
建立索引最簡單也直觀的方式,是透過鍵值對的方式開始。舉例來說,可以透過一個雜湊表(hash map) 來實作這個簡易索引。在資料庫寫入新資料的同時,可以在記憶體同時更新雜湊表,表中的鍵會對映到硬碟中的某個位置,這樣一來要在硬碟中找某筆資料時,就不用掃過整個硬碟檔案,而是可以直接跳到硬碟中存該資料的位置。
但這種做法也有明顯的限制在,一來如果不斷新增鍵,記憶體最終會被佔滿;二來因為存在記憶體,如果機器關閉重開後,索引就會消失,需要重新掃過硬碟來重建。除此之外,因為用雜湊的方式,雜湊值分佈是沒有序的,需要掃過整個雜湊表的對應關係才能做範圍查詢,導致做範圍的查詢效率會比較差。
SSTable
因為上面提到的問題,雜湊表很少真的被用來做資料庫的索引。更常見的做法,是讓鍵不是隨機排列而是按照順序排列的,SSTable (Sorted String Table) 即是一種按鍵排序的實作方式。
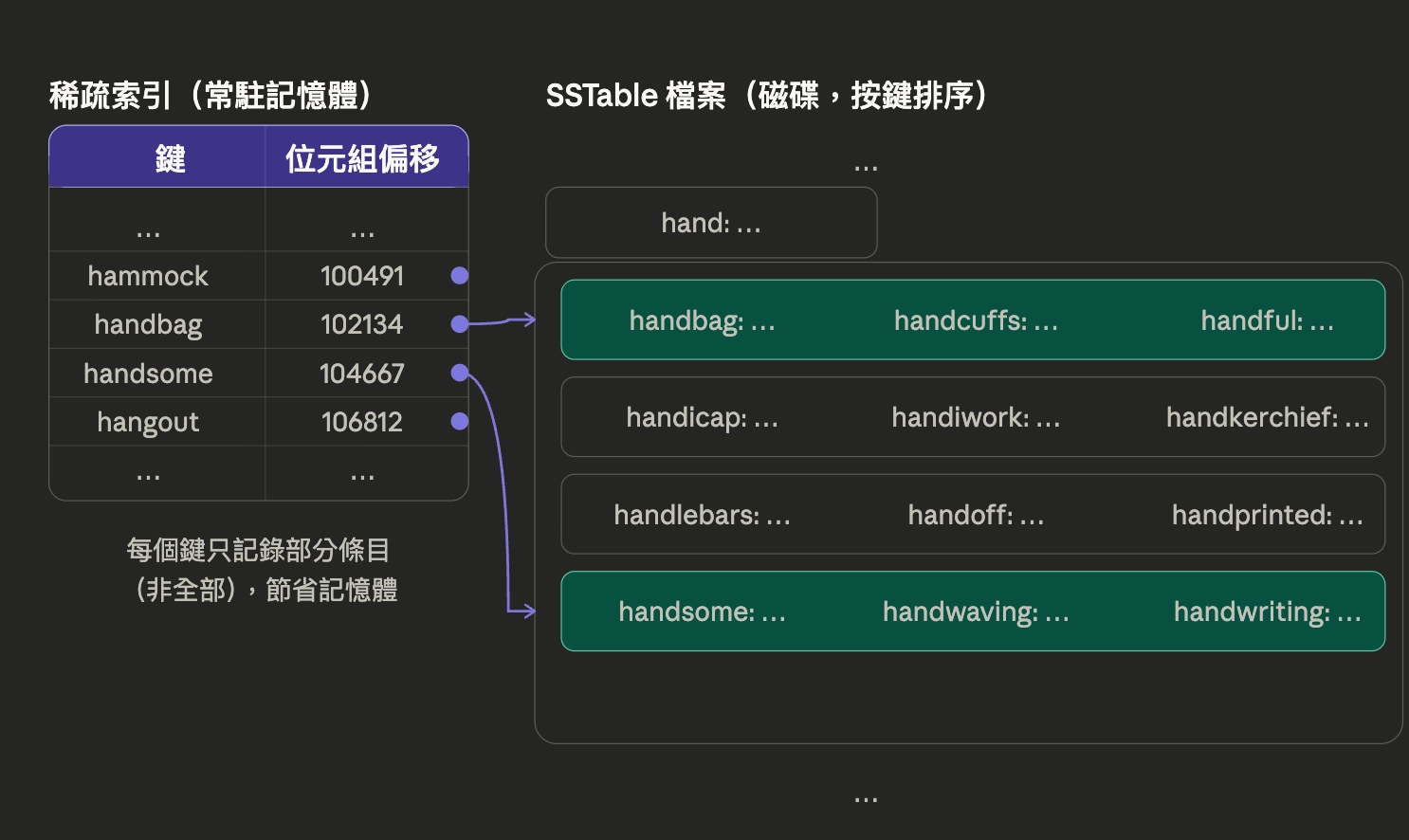
從上圖範例中可以看到 SSTable 有三大改善之處,分別是
- 降低記憶體用量:透過稀疏索引 (sparse index) 把索引分區塊,第一塊的鍵是
handbag,第二塊是handsome。這時如果在記憶體中尋找鍵handiwork,雖然沒直接在索引表中,但因為該詞的偏移量在handbag與handsome之間,所以能在handbag這個區塊找。用這種方式,能大幅降低常住在記憶體空間的鍵的數量。 - 讓範圍查詢效率更高:假如用單純雜湊來搜
handsome和hello之間的詞,因為是隨機打散,排列沒有任何順序可言。所以只能用WHERE key BETWEEN 'hand' AND 'hang'這種查詢只做全表掃描,效率不高。但因為 SSTable 有分塊,所以可以直接去對應的區塊搜,效率會高很多。 - 壓縮減少硬碟空間與 I/O 頻寬:因為 SSTable 有分塊,不像雜湊表完全隨機,所以可以透過 LZ4 之類的演算法,把有共同前綴的字串做壓縮 (例如
handbag、handcuffs、handful、handicap都有hand這個前綴),這樣就能減少硬碟空間的佔用,也讓 I/O 時的頻寬佔用降低。
單純的 SSTable 雖然在查詢上能帶來上面的改善,但是寫入上成本會高一點。舉例來說,如果要在上面的 SSTable 範例寫入 "handlebars"。這時磁碟檔案不能直接插入一格,沒辦法把後面的所有資料往後推一格,所以必須把整個檔案重寫一遍。如果檔案大到一定規模,為了插入一個鍵就要寫的量很大,從擴展角度來說不理想。
因此,在業界通常會搭配記憶體表 (memtable),先在記憶體中排序好。這時因為寫到磁碟時已經排好了,是一次按順序寫入,不需要有插入的動作,所以比隨機寫快很多。同時在移除某個鍵時,會搭配另一個記錄表 (tombstone) 來記錄某個已被刪除的鍵,在合併階段時再移除。
這種做法又被稱為 LSM,LS 是 Log-Structured 的做法即代表所有寫入都是追加,都是先排好順序再寫新檔案,而不是在舊檔案中間插入。而 M 是 Merge,在更新或刪除時透過 tombstone 記錄,在合併同一個鍵只留最新的值。
布隆過濾器 (Bloom Filter)
上面提到的 SSTable 與 LSM,雖然已經有極大的改善,但是如果讀某個不存在的鍵,效率不是太好,因為要先掃過這個記憶體表,以及逐層查找多個 SSTable,才能確認該鍵不存在。因此,通常實作上會搭配額外的布隆過濾器 (Bloom Filter),來得知資料庫中是否存在某個鍵,從而為不存在的鍵節省掉許多不必要的硬碟讀取操作。

從上圖可以看到,布隆過濾器是一個位元陣列 (bit array)。在寫入 SSTable 時,對每個鍵跑 k 個雜湊函式,把結果對應的位元位置設為 1。如圖中所示,"handbag" 把位元 2、4、9 設為 1,"handoff" 把位元 5、9、15 設為 1。
查詢 "handheld" 時,同樣跑雜湊函式,得到位元 6、11、2。這時只要任一位元為 0,就能確定這個鍵從未被插入,因為插入時會把所有對應的位元都設為 1。位元 6 = 0,所以直接跳過,不需要讀取磁碟。
透過這個額外的資料結構,我們能夠避免掃過整個 SSTable 就知道某個值不存在。因為布隆過濾器對比起整個 SSTable,佔用的空間小很多,所以加上這個額外資料結構,也是用小空間換取加快時間的好做法。
B 樹
前面作者談了 LSM 樹的做法,不過在業界中有另一個更流行的索引結構是 B 樹。先前我們在 資料庫索引 (database index) 是什麼? 如何選擇加在哪個欄位上? 一文中有詳細談過 B 樹與 B+ 樹,所以這邊就先不詳細談摘要,推薦讀者們可以回顧。往下作者比較了 LSM 樹與 B 樹的優缺點。
LSM 樹比起 B 樹的優勢在於,寫入時不需要覆寫整頁,比起 B 樹的整體磁碟使用更有效率。同時,寫入時的 I/O 不是隨機的 (B 樹是隨機的),所以吞吐量相對比較高。兩相比較下,如果使用情境更偏向寫多讀少,LSM 會比較合適。
B 樹比起 LSM 樹的優勢則在於層級比較少,所以讀取的速度相對快;LSM 樹在查詢時可能要讀多個 SSTable,雖可以透過布隆過濾器加速某些情境,但不如 B 樹穩定。此外,由於資料本身有排序,在做範圍查詢時可以直接掃描,不需像 LSM 樹還得合併多個來源,整體的效率比較高。因此,在讀比較多的情境下,B 樹會比較合適。
閱讀更多
除了上面提到的點,在 DDIA 第四章,作者還談到了其他類型的索引比較,如果你對完整 DDIA 第四章的導讀感興趣,我們在 E+ 會員方案中的主題文,有完整的版本。對更深入了解這個主題,以及其他前後端開發、軟體工程、AI 工程主題感興趣的讀者,歡迎加入 E+ 一起成長 (連結)。