1-4 Beyond Text: Using Images and Voice to Code Faster
April 19, 2025
This article explores how Cursor's multimodal features—images and voice input—can transform your development workflow beyond traditional text-based interactions. These capabilities make AI assistance more intuitive and effective for visual tasks.
I needed to build a custom dropdown component based on a designer's mockup. My first instinct was to describe it in text: "Create a dropdown with rounded corners, specific padding, a subtle shadow..." But translating visual designs into detailed text descriptions is tedious and error-prone.
Then I tried Cursor's image upload feature. I took a screenshot of the design and pasted it directly into the chat, along with a simple instruction: "Build this component in React with Tailwind CSS." The AI could see exactly what I wanted and generated code that was much closer to the intended design than my text description would have produced. This experience showed me how multimodal features can make AI assistance more effective and intuitive.
What Multimodal Really Means
When we say an AI is "multimodal," we mean it can understand and work with different types of information. Instead of just reading text, it can analyze images and understand visual layouts, process voice commands and convert speech to text, and handle multiple input types simultaneously.
This changes how developers can interact with AI. When you're building a user interface, you're constantly translating visual concepts into code. The closer you can get your AI assistant to see what you see, the better it can help you build what you want.
Image Upload: Show, Don't Tell
The most practical multimodal feature in Cursor is image upload. This is particularly powerful for frontend development, where precision matters.
Real-World Example: Building from Design
Let's say you need to recreate a payment form from a design mockup. Instead of describing every detail in text, you can capture the design by taking a screenshot of the mockup, Figma design, or even a hand-drawn sketch. Then paste it directly into Cursor—the image appears as a preview tag that you can hover over to verify it's correct. Add context with text like "Build this payment form in React using TypeScript and Tailwind CSS," and Cursor will analyze the visual layout and generate matching code.
Why This Works Better Than Text Descriptions
Try describing a complex layout in words. You'll end up with paragraphs of detailed specifications about spacing, colors, alignment, and hierarchy. The AI has to interpret your description and might miss subtle details or misunderstand proportions.
With an image, the AI sees exactly what you want. It can identify visual hierarchy and component relationships, recognize spacing and layout patterns, understand color schemes and design consistency, and spot interactive elements and their states. This visual understanding leads to code that's much closer to your intended design.
Voice Input: Coding by Speaking
Voice input might sound gimmicky, but it's surprisingly effective for certain workflows. This requires a third-party tool, but the setup is straightforward.
Google's Addy Osmani wrote an excellent article called Speech-to-Code: Vibe Coding with Voice, where he recommends SuperWhisper.
Setting up SuperWhisper is straightforward: visit superwhisper.com to download the app, install it and configure your preferred hotkeys, then open both SuperWhisper and Cursor to start speaking your code instructions.
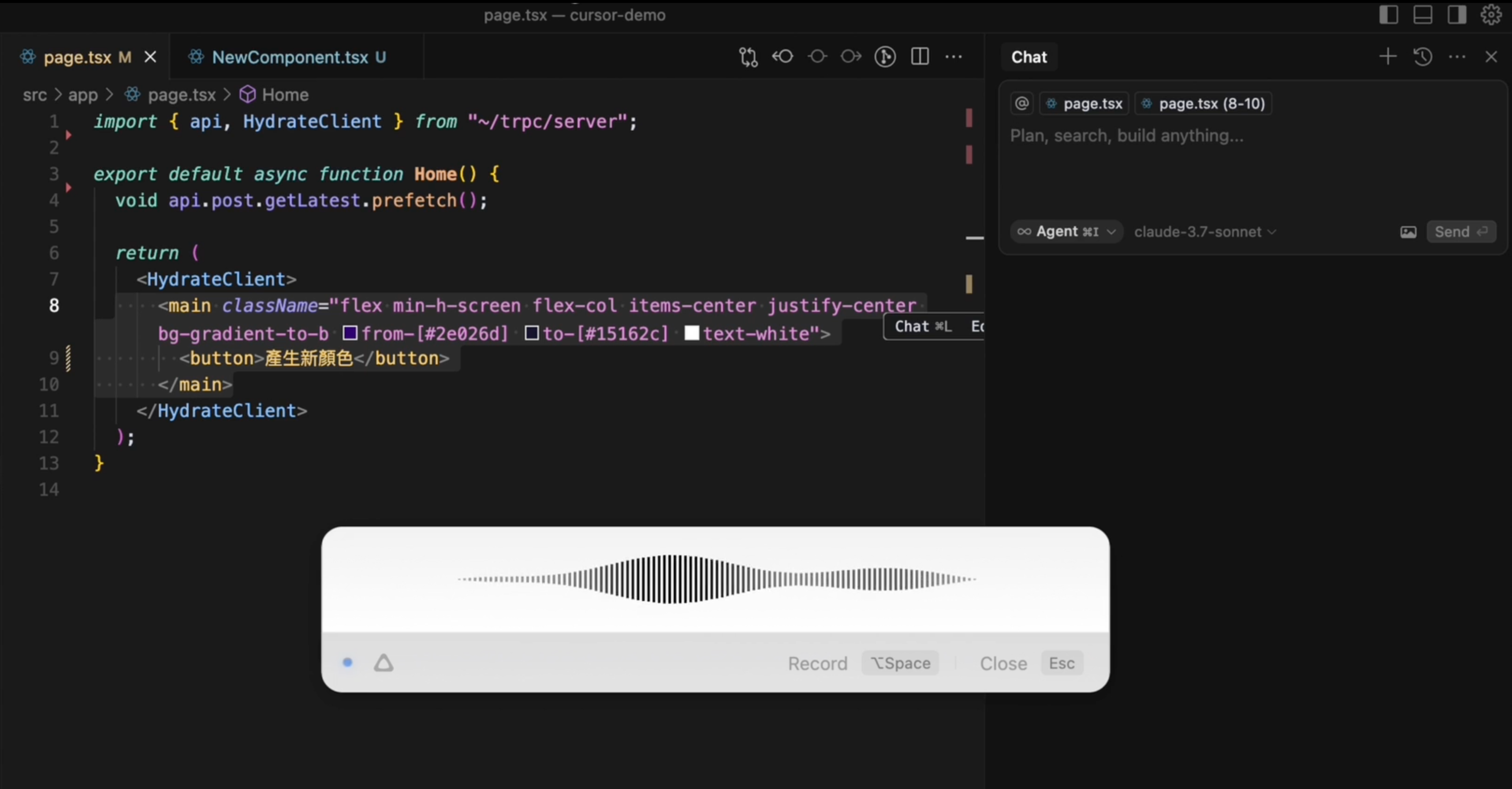
Building Your Multimodal Toolkit
These features aren't daily drivers for most developers, but they're powerful when you need them. The key is knowing when each approach works best:
Use images when building UI components from designs, recreating layouts you've seen elsewhere, debugging visual issues, or working with complex diagrams or flowcharts.
Use voice when planning complex features out loud, your hands are busy with other tasks, you have detailed requirements that are faster to speak than type, or accessibility considerations make typing difficult.
Stick with text when making small specific changes, working with pure logic or algorithms, or when precision is critical and ambiguity is dangerous.
The goal isn't to use every feature for every task—it's to have these tools available when they make your work significantly easier or faster.
In the next chapter, we'll dive into prompt engineering—how to craft instructions that get you exactly the results you want from AI.
Support ExplainThis
If you found this content valuable, please consider supporting our work with a one-time donation of whatever amount feels right to you through this Buy Me a Coffee page.
Creating in-depth technical content takes significant time. Your support helps us continue producing high-quality educational content accessible to everyone.